As a maintainer of PouchDB, I get a lot of questions from developers about how best to work with databases. Since PouchDB is a JavaScript library, and one with fairly approachable documentation (if I do say so myself), many of these folks tend toward the more beginner-ish side of the spectrum. However, even with experienced developers, I find that many of them don’t have a clear picture of how a database should fit into their overall app structure.
The goal of this article is to lay out my perspective on the proper place for a database within your app code. My focus will be on the frontend – e.g. SQLite in an Android app, CoreData in an iOS app, or IndexedDB in a webapp – but the discussion could apply equally well to a server-side app using MongoDB, MySQL, etc.
What is a database, anyway?
I have a friend who recently went through a developer bootcamp. He’s a smart guy, but totally inexperienced with JavaScript (or any kind of coding) before he started. So I found his questions endlessly fascinating, because they reminded me what it was like learning to code.
Part of his coursework was on MongoDB, and I recall spending some time coaching him on Mongoose queries. As I was explaining the concepts to him, he got a little frustrated and asked, “What’s the point of a database, anyway? Why do I need this thing?”
For a beginner, this is a perfectly valid question. You’ve already spent a long time learning to work with data in the form of objects and arrays (or “dictionaries” and “lists,” or whatever your language calls them), and now suddenly you’re told you need to learn about this separate thing called a “database” that has similar kinds of operations, but they’re a lot more awkward. Instead of your familiar for-loops and assignments, you’re structuring queries and defining schemas. Why all the overhead?
To answer that question, let’s take a step back and remember why we have databases in the first place.
#1 goal of a database: don’t forget stuff
When you create an object or an array in your code, what you have is data:
var array = [1, 2, 3, 4, 5];
This data feels tangible. You can iterate through it, you can print it out, you can insert and remove things, and you can even .map() and .filter() it to transform it in all sorts of interesting ways. Data structures like this are the raw material your code is made of.
However, there’s an ephemeral side to this data. We happen to call the space that it lives in “memory” or “RAM” (Random Access Memory), but in fact “memory” is kind of a nasty misnomer, because as soon as your application stops, that data is gone forever.
You can imagine that if computers only had memory to work with, then computer programs would be pretty frustrating to use. If you wanted to write a Word document, you’d need to be sure to print it out before you closed Word, because otherwise you’d lose your work. And of course, once you restarted Word, you’d have to laboriously type your document back in by hand. Even worse, if you ever had a power outage or the program crashed, your data would vanish into the ether.
Thankfully, we don’t have to deal with this awful scenario, because we have hard disks, i.e. a place where data can be stored more permanently. Sometimes this is called “storage,” so for instance when you buy a new laptop with 200GB of storage but only 8GB of RAM, you’re looking at the difference between disk (or storage) and memory (or RAM). One is permanent, the other is fleeting.
So if disk is so awesome, why don’t computers just use that? Why do we have RAM at all?
Well, the reason for that is that there’s a pretty big tradeoff in speed between “storage” and “memory.” You’ve felt it if you’ve ever copied a large file to a USB stick, or if you’ve seen an old low-RAM machine that look a long time to switch between windows. That’s called paging, and it’s when your computer runs out of RAM, so it starts hot-swapping between RAM and disk.

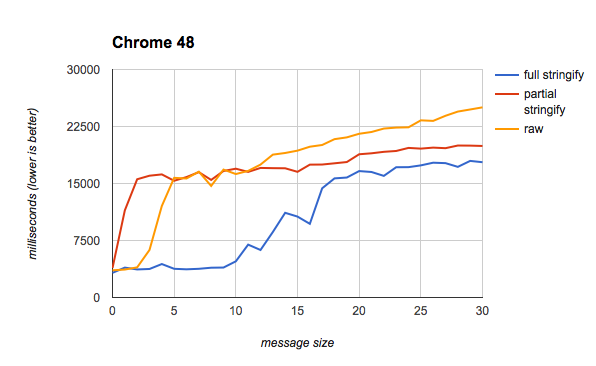
Latency numbers, visualized.
This performance difference cannot be overstated. If you look at a chart of latency numbers every programmer should know, you’ll see that reading 1MB sequentially from memory takes about 250 microseconds, whereas reading 1MB from disk is 20 milliseconds. If those numbers both sound small, consider the scale: if 250 microseconds were the time it took to brush your teeth (5 minutes, if you listen to your dentist!), then 20 milliseconds would be 4.6 days, which is enough time to drive east-to-west across North America, with plenty of breaks in between.
And if you think reading 1MB from SSD is much better (1 millisecond), then consider that in our toothbrush-scale, it would still be 5.5 hours. That’s the time it would take for you to fly from New York to San Francisco, which is quite a bit shorter than our road trip, but still something you’d need to pack your bags for.
In a computer program, the kind of operations you can “get away with” in the toothbrush-scale of 5 minutes are totally different than what you can do in 5 hours or 4 days. This is the difference between a snappy application and a sluggish application, and it’s also at the heart of how you should be thinking about databases within your app.
Storage vs memory
Let’s move away from toothbrushes for a moment and try a different analogy. This is the one I find most useful myself when I’m writing an app.
Memory (including objects, arrays, variables, etc.) are like the counter space in your kitchen when you’re preparing a meal. You have all the tools available to you, you can quickly chop your carrots and put them into a bowl, you can mix the onions with the celery, and all of these things can be done fairly quickly without having to move around the kitchen.
Storage, on the other hand (including filesystems and databases) are like the freezer. It’s a place where you put food that you know you’re going to need later. However, when you pull it out of the freezer, there’s often a thawing period. You also don’t want to be constantly opening your freezer to pull ingredients in and out, or your electric bill is going to go through the roof! Plus, your food will probably end up tasting awful.
Probably the biggest mistake I see beginners make when working with databases is that they want to treat their freezer like their counter space. They want their application data to be perfectly mirrored in their database schemas, and they don’t want to have to think about where their food comes from – whether it’s been sitting on the counter for a few seconds, or in the freezer for a few days.
This is at the root of a lot of suffering when working with databases. You either end up constantly reading things in and out of disk, which means that your app runs slowly (and you probably blame your database!), or you have to meticulously manage your schemas and painstakingly migrate your data whenever anything in your in-memory representation changes.
Unfortunately, this idea that we can treat our databases like our RAM is a by-product of the ORM (Object-Relational Mapping) mentality, which in my opinion is one of the most toxic and destructive ideas in software engineering, because it sells you a false vision of hope. The ORM salesman promises that you can work with your in-memory objects and make them as fancy as you like, and then magically those objects will be persisted to the database (exactly as you left them!), and you’ll never even have to think about what a database is or how you’re accessing it.
In my experience, this is never how it works out with ORMs. It may seem easy at first, but eventually your usage of the database will become inefficient, and you’ll have to drop down into the murky details of the ORM layer, figure out the queries you wish it were doing, and then try to guess the incantation needed to make it perform that query. In effect, the promise of not having to think about the database is a sham, because you just end up just having to learn two layers: the database layer and the ORM layer. It’s a classic leaky abstraction.
Even if you manage to tame your ORM, you usually end up with a needlessly complex schema format, as the inflexibility of working with stored data collides with the needs of a flexible in-memory format. You might find that you wind up with a SQLite table with 20 columns, merely because your class has 20 variables – even if none of those 20 columns are ever used for querying, and in fact are just wasted space.
This partially explains the attraction of NoSQL databases, but I believe that even without rigid schemas, this problem of the “ORM mindset” remains. Mongoose is a good example of this, as it tries to mix JavaScript and MongoDB in a way that you can’t tell where one starts and the other ends. Invariably, though, this leads developers to hope that their in-memory format can exactly match their database format, which leads to irreconcilable situations (such as classes with behavior) or slowdowns (such as over-fetching or over-storing).
All of this is pretty abstract, so let me take some concrete examples from a recent app I wrote, Pokedex.org, and how I carefully modeled my database structure to maximize performance. (If you’re unfamiliar with Pokedex.org, you may want to read the introductory blog post.)
Case study: Pokedex.org
The first consideration I had to make for Pokedex.org was which database to use in the first place. Without going into the details of browser databases, I ended up choosing two:
- LocalForage, because it has a simple key-value API that’s good for storing application state.
- PouchDB, because it has good APIs for working with larger datasets, and can serve as an offline-first layer in front of Cloudant or CouchDB.
PouchDB can also store key-value data, so I might have used it for both. However, another benefit of LocalForage is that the bundle size is much smaller (8KB vs PouchDB’s 45KB). And in my case I had three JavaScript bundles (one for the service worker, one for the web worker, and one for the main JavaScript app), so I didn’t want to push 45KB down the wire three times. Hence I chose LocalForage for the simple stuff.

Pokedex.org database usage
You can see what kind of data I stored in LocalForage if you go into the Chrome Dev Tools on Pokedex.org and open the “Resources” tab. You’ll see I’m using it to store the ServiceWorker data version (so it knows when to update), as well as "informedOffline", which just tells me whether I’ve already shown the dialog that says, “Hey, this app works offline.” If I had more app data to store (such as the user’s favorite Pokémon, or how many times they’ve opened the app), I might store that in LocalForage.
PouchDB, however, is responsible for storing the majority of the Pokémon data – i.e. the 649 species of monsters, their stats, and their moves. So this is much more interesting.
First off, you’ll notice that as you type into the search bar, you immediately get a filtered list showing Pokémon that match your search string. This is a simple prefix search, so if you type “bu” you will see “Bulbasaur” and “Butterfree” amongst others.
This search bar is super fast, and it ought to be, because it’s supposed to respond to user input. There’s a debounce on the actual <input> handler, but in principle every keystroke represents a database query, meaning that there’s a lot of data flying back and forth.
I considered using PouchDB for this, but I decided it would be too slow. PouchDB does offer built-in prefix search, but I don’t want to have to go back and forth to IndexedDB (i.e. disk) for every keystroke. So instead, I wrote a simple in-memory database layer that stores Pokémon summary data, i.e. only the things that are necessary to show in the list, which happens to be their name, number, and types. (The sprite comes from a CSS class based on their number.)
To perform the search itself, I just used a sorted array of String names, with a binary search to ensure that lookups take O(log n) time. If the list were larger, I might try to condense it as a trie, but I figured that would be overkill for this app.
For a small amount of data, this in-memory strategy works great. However, when you click on a Pokémon, it brings up a detail page with stats, evolutions, and moves, which is much too large to keep in memory. So for this, I used PouchDB.
Given that I am the primary author of PouchDB map/reduce, relational-pouch, and pouchdb-find, you may be surprised to learn that I didn’t use any of them for this task. Obviously I put a lot of care into those libraries, and I do think they’re useful for beginners who are unsure how to structure their data. But from a performance standpoint, none of them can beat the potential gains from rolling your own, so that’s what I did.
In this case, I used my knowledge of IndexedDB performance subtleties to get the maximum possible throughput in the shortest amount of time. Essentially, what I did was split up my data into seven separate PouchDB databases, representing seven different IndexedDB databases on disk:
- Monster basic data
- Monster descriptions
- Monster evolutions
- Monster supplemental data (anything not covered above)
- Types
- Monster moves
- Moves
The first four all use IDs based on the number of the Pokémon (e.g. Bulbasaur is 1, Ivysaur is 2, etc.), and map to data such as evolutions, stats, and descriptions. This means that tapping on a Pokémon involves a simple key-value lookup.
The reason I segmented this data into multiple databases is because IndexedDB happens to do a lot of transaction-level blocking at the database level. If you have the luxury of specifying separate IndexedDB objectStores, you can allow your databases queries to run in parallel under the hood, but in the case of PouchDB all of the objectStores are predefined (due to the CouchDB-style revision semantics written on top of IndexedDB).
In practice, this usually means that read/write operations (such as the initial import of the data) will run sequentially unless you use separate PouchDB objects. Sequential is bad – we want the database to do as much work as quickly as possible – so I avoided using one large PouchDB database. (If you were using a lower-level library like Dexie, though, you could use a single database with separate objectStores and probably get a similar result.)
So when you tap on a Pokémon, the app fires off six concurrent get() requests, which the underlying IndexedDB layer is free to run in parallel. This is why you barely have to wait at all to see the Pokémon data, although it helps that I have a snazzy animation while the lookup is in progress. (Animations are a great way to mask slow operations!) The query is also run in a web worker, which is why you won’t see any UI blocking from IndexedDB during database interactions.

A Pokémon’s type(s) determine its strengths/weaknesses relative to other types
Now, two of the six requests I described above are for a Pokémon’s “type” information, which merit some explanation. Each Pokémon has up to two types (e.g. Fire and Water), and types also have strengths and weaknesses relative to each other: Fire beats Grass, Water beats Fire, etc. The “types” database contains this big rock-paper-scissors grid, which isn’t keyed by Pokémon ID like the other four, but rather by type name.
However, since the type names of each Pokémon are already available in-memory (due to the summary view), the queries for a Pokémon’s strengths and weaknesses can be fired off in parallel with the other queries. And since they’re equally simple get() requests, they take about the same amount of time to complete. This was a nice side effect of my previous in-memory optimizations.
The last two databases are a bit trickier than the others, and are quite relation-y. I called these the “monster moves” and “moves” databases, and I modeled their implementation after relational-pouch (although I didn’t feel the need to use relational-pouch itself).
Essentially, the “monster moves” database contains a mapping from monster IDs to a list of learned moves (e.g. Bulbasaur learns Razor Leaf at level 27), while the “moves” database contains a mapping from move IDs to information about the move (e.g. Razor Leaf has a certain power, accuracy, and description). If you’re familiar with SQL, you might recognize that I would need a JOIN to combine this data together, although in my case I just did the join explicitly myself, in JavaScript.
Since this is a many-to-many relationship (Pokémon can learn many moves, and moves can be learned by many Pokémon), it would be prohibitively redundant to include the “move” data inside the “monster move” database – that’s why I split it apart. However, the relational query (i.e. the JOIN) has a cost, and I saw it while developing my app – it takes nearly twice as long to fetch the full “moves” data (75ms on a Nexus 5X) as it does to fetch the more basic data (40ms – these numbers are much larger on a slow device). So what to do?
Well, I pulled off a sleight-of-hand. You’ll notice that, especially in a mobile browser, the list of Pokémon moves is “below the fold.” Thus, I can simply load the above-the-fold data first, and then lazily fetch the rest before the user has scrolled down. On a fast mobile browser, you probably won’t even notice that anything was fetched in two stages, although on a huge monitor you might be able to glimpse it. (I considered adding a loading spinner, but the “moves” data was already fast enough that I felt it was unnecessary.)
So there you have it: the queries that ought to feel “instant” are done in memory, the queries that take a bit longer are fetched in parallel (with an animation to keep the eye busy), and the queries that are super slow are slipped in below-the-fold. This is a subtle ballet with lots of carefully orchestrated movements, and the end result is an app that feels pretty seamless, despite all the work going on behind the scenes.
Conclusion
When you’re working with databases, it’s worthwhile to understand the APIs you’re dealing with, and what they’re doing under the hood. Unfortunately, databases are not magic, and there’s no abstraction in the world (I believe) that can obviate the need to learn at least a little bit about how a database works.
So when you’re using a database, be sure to ask yourself the following questions:
- Is this database in-memory (Redis, LokiJS, MemDOWN, etc.) or on-disk (PouchDB, LocalForage, Lovefield, etc.)? Is it a mix between the two (e.g. LevelDB)?
- What needs to be stored on disk? What data should survive the application being closed or crashing?
- What needs to be indexed in order to perform fast queries? Can I use an in-memory index instead of going to disk?
- How should I structure my in-memory data relative to my database data? What’s my strategy for mapping between the two?
- What are the query needs of my app? Does a summary view really need to fetch the full data, or can it just fetch the little bit it needs? Can I lazy-load anything?
Once you’ve answered these questions, you can write an app that is fast, responsive, and doesn’t lose user data. You’ll also make your own job easier as a programmer, if you try to maintain a good grasp of the differences between your in-memory data (your counter space) and your on-disk data (your freezer).
Nobody likes freezer burn, but spoiled meat that’s been left on the counter overnight is even worse. Understand the difference between the two, and you’ll be a master chef in no time.
Notes
Of course there are more advanced topics I could have covered here, such as indexes, sync, caching, B-trees, and on and on. (We could even extend the metaphor to talk about “tagging” food in the freezer as an analogy for indexing!) But I wanted to keep this blog post small and focused, and just communicate the bare basics of the common mistakes I’ve seen people make with databases.
I also apologize for all the abstruse IndexedDB tricks – those probably merit their own blog post. In particular, I need to provide some experimental data to back up my claim that it’s better to break up a single IndexedDB database into multiple smaller ones. This trick is based on my personal experience with IndexedDB, where I noticed a high cost of fetching and storing large monolithic documents, but I should do a more formal study to confirm it.
Thanks to Nick Colley, Chris Gullian, Jan Lehnardt, and Garren Smith for feedback on a draft of this blog post.