Update: this post was updated with some new benchmark numbers in October 2022.
Last year, I asked the question: Does shadow DOM improve style performance? I didn’t give a clear answer, so perhaps it’s no surprise that some folks weren’t sure what conclusion to draw.
In this post, I’d like to present a new benchmark that hopefully provides a more solid answer.
TL;DR: My new benchmark largely confirmed my previous research, and shadow DOM comes out as the most consistently performant option. Class-based style scoping slightly beats shadow DOM in some scenarios, but in others it’s much less performant. Firefox, thanks to its multi-threaded style engine, is much faster than Chrome or Safari.
Shadow DOM and style performance
To recap: shadow DOM has some theoretical benefits to style calculation, because it allows the browser to work with a smaller DOM size and smaller CSS rule set. Rather than needing to compare every CSS rule against every DOM node on the page, the browser can work with smaller “sub-DOMs” when calculating style.
However, browsers have a lot of clever optimizations in this area, and userland “style scoping” solutions have emerged (e.g. Vue, Svelte, and CSS Modules) that effectively hook into these optimizations. The way they typically do this is by adding a class or an attribute to the CSS selector: e.g. * { color: red } becomes *.xxx { color: red }, where xxx is a randomly-generated token unique to each component.
After crunching the numbers, my post showed that class-based style scoping was actually the overall winner. But shadow DOM wasn’t far behind, and it was the more consistently fast option.
These nuances led to a somewhat mixed reaction. For instance, here’s one common response I saw (paraphrasing):
The fastest option overall is class-based scoped styles, ala Svelte or CSS Modules. So shadow DOM isn’t really that great.
But looking at the same data, you could reach another, totally reasonable, conclusion:
With shadow DOM, the performance stays constant instead of scaling with the size of the DOM or the complexity of the CSS. Shadow DOM allows you to use whatever CSS selectors you want and not worry about performance.
Part of it may have been people reading into the data what they wanted to believe. If you already dislike shadow DOM (or web components in general), then you can read my post and conclude, “Wow, shadow DOM is even more useless than I thought.” Or if you’re a web components fan, then you can read my post and think, “Neat, shadow DOM can improve performance too!” Data is in the eye of the beholder.
To drive this point home, here’s the same data from my post, but presented in a slightly different way:

Click for details
This is 1,000 components, 10 rules per component.
| Selector performance (ms) |
Chrome |
Firefox |
Safari |
| Class selectors |
58.5 |
22 |
56 |
| Attribute selectors |
597.1 |
143 |
710 |
| Class selectors – shadow DOM |
70.6 |
30 |
61 |
| Attribute selectors – shadow DOM |
71.1 |
30 |
81 |
As you can see, the case you really want to avoid is the second one – bare attribute selectors. Inside of the shadow DOM, though, they’re fine. Class selectors do beat shadow DOM overall, but only by a rounding error.
My post also showed that more complex selectors are consistently fast inside of the shadow DOM, even if they’re much slower at the global level. This is exactly what you would expect, given how shadow DOM works – the real surprise is just that shadow DOM doesn’t handily win every category.
Re-benchmarking
It didn’t sit well with me that my post didn’t draw a firm conclusion one way or the other. So I decided to benchmark it again.
This time, I tried to write a benchmark to simulate a more representative web app. Rather than focusing on individual selectors (ID, class, attribute, etc.), I tried to compare a userland “scoped styles” implementation against shadow DOM.
My new benchmark generates a DOM tree based on the following inputs:
- Number of “components” (web components are not used, since this benchmark is about shadow DOM exclusively)
- Elements per component (with a random DOM structure, with some nesting)
- CSS rules per component (randomly generated, with a mix of tag, class, attribute,
:not(), and :nth-child() selectors, and some descendant and compound selectors)
- Classes per component
- Attributes per component
To find a good representative for “scoped styles,” I chose Vue 3’s implementation. My previous post showed that Vue’s implementation is not as fast as that of Svelte or CSS Modules, since it uses attributes instead of classes, but I found Vue’s code to be easier to integrate. To make things a bit fairer, I added the option to use classes rather than attributes.
One subtlety of Vue’s style scoping is that it does not scope ancestor selectors. For instance:
/* Input */
div div {}
/* Output - Vue */
div div[data-v-xxx] {}
/* Output - Svelte */
div.svelte-xxx div.svelte-xxx {}
(Here is a demo in Vue and a demo in Svelte.)
Technically, Svelte’s implementation is more optimal, not only because it uses classes rather than attributes, but because it can rely on the Bloom filter optimization for ancestor lookups (e.g. :not(div) div → .svelte-xxx:not(div) div.svelte-xxx, with .svelte-xxx in the ancestor). However, I kept the Vue implementation because 1) this analysis is relevant to Vue users at least, and 2) I didn’t want to test every possible permutation of “scoped styles.” Adding the “class” optimization is enough for this blog post – perhaps the “ancestor” optimization can come in future work. (Update: this is now covered below.)
Note: In benchmark after benchmark, I’ve seen that class selectors are typically faster than attribute selectors – sometimes by a lot, sometimes by a little. From the web developer’s perspective, it may not be obvious why. Part of it is just browser vendor priorities: for instance, WebKit invented the Bloom filter optimization in 2011, but originally it only applied to tags, classes, and IDs. They expanded it to attributes in 2018, and Chrome and Firefox followed suit in 2021 when I filed these bugs on them. Perhaps something about attributes also makes them intrinsically harder to optimize than classes, but I’m not a browser developer, so I won’t speculate.
Methodology
I ran this benchmark on a 2021 MacBook Pro (M1), running macOS Monterey 12.4. The M1 is perhaps not ideal for this, since it’s a very fast computer, but I used it because it’s the device I had, and it can run all three of Chrome, Firefox, and Safari. This way, I can get comparable numbers on the same hardware.
In the test, I used the following parameters:
| Parameter |
Value |
| Number of components |
1000 |
| Elements per component |
10 |
| CSS rules per component |
10 |
| Classes per element |
2 |
| Attributes per element |
2 |
I chose these values to try to generate a reasonable “real-world” app, while also making the app large enough and interesting enough that we’d actually get some useful data out of the benchmark. My target is less of a “static blog” and more of a “heavyweight SPA.”
There are certainly more inputs I could have added to the benchmark: for instance, DOM depth. As configured, the benchmark generates a DOM with a maximum depth of 29 (measured using this snippet). Incidentally, this is a decent approximation of a real-world app – YouTube measures 28, Reddit 29, and Wikipedia 17. But you could certainly imagine more heavyweight sites with deeper DOM structures, which would tend to spend more time in descendant selectors (outside of shadow DOM, of course – descendant selectors cannot cross shadow boundaries).
For each measurement, I took the median of 5 runs. I didn’t bother to refresh the page between each run, because it didn’t seem to make a big difference. (The relevant DOM was being blown away every time.) I also didn’t randomize the stylesheets, because the browsers didn’t seem to be doing any caching that would require randomization. (Browsers have a cache for stylesheet parsing, as I discussed in this post, but not for style calculation, insofar as it matters for this benchmark anyway.)
Update: I realized this comment was a bit blasé, so I re-ran the benchmark with a fresh browser session between each sample, just to make sure the browser cache wasn’t affecting the numbers. You can find those numbers at the end of the post. (Spoiler: no big change.)
Although the benchmark has some randomness, I used random-seedable with a consistent seed to ensure reproducible results. (Not that the randomness was enough to really change the numbers much, but I’m a stickler for details.)
The benchmark uses a requestPostAnimationFrame polyfill to measure style/layout/paint performance (see this post for details). To focus on style performance only, a DOM structure with only absolute positioning is used, which minimizes the time spent in layout and paint.
And just to prove that the benchmark is actually measuring what I think it’s measuring, here’s a screenshot of the Chrome DevTools Performance tab:
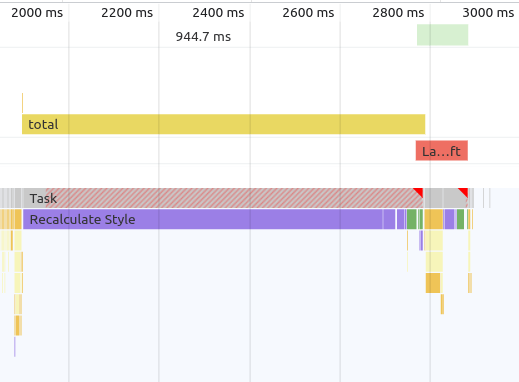
Note that the measured time (“total”) is mostly taken up by “Recalculate Style.”
Results
When discussing the results, it’s much simpler to go browser-by-browser, because each one has different quirks.
One of the things I like about analyzing style performance is that I see massive differences between browsers. It’s one of those areas of browser performance that seems really unsettled, with lots of work left to do.
That is… unless you’re Firefox. I’m going to start off with Firefox, because it’s the biggest outlier out of the three major browser engines.
Firefox
Firefox’s Stylo engine is fast. Like, really fast. Like, so fast that, if every browser were like Firefox, there would be little point in discussing style performance, because it would be a bit like arguing over the fastest kind of for-loop in JavaScript. (I.e., interesting minutia, but irrelevant except for the most extreme cases.)
In almost every style calculation benchmark I’ve seen over the past five years, Firefox smokes every other browser engine to the point where it’s really in a class of its own. Whereas other browsers may take over 1,000ms in a given scenario, Firefox will take ~100ms for the same scenario on the same hardware.
So keep in mind that, with Firefox, we’re going to be talking about really small numbers. And the differences between them are going to be even smaller. But here they are:

Click for table
| Scenario |
Firefox 101 |
| Scoping – classes |
30 |
| Scoping – attributes |
38 |
| Shadow DOM |
26 |
| Unscoped |
114 |
Note that, in this benchmark, the first three bars are measuring roughly the same thing – you end up with the same DOM with the same styles. The fourth case is a bit different – all the styles are purely global, with no scoping via classes or attributes. It’s mostly there as a comparison point.
My takeaway from the Firefox data is that scoping with either classes, attributes, or shadow DOM is fine – they’re all pretty fast. And as I mentioned, Firefox is quite fast overall. As we move on to other browsers, you’ll see how the performance numbers get much more varied.
Chrome
The first thing you should notice about Chrome’s data is how much higher the y-axis is compared to Firefox. With Firefox, we were talking about ~100ms at the worst, whereas now with Chrome, we’re talking about an order of magnitude higher: ~1,000ms. (Don’t feel bad for Chrome – the Safari numbers will look pretty similar.)

Click for table
| Scenario |
Chrome 102 |
| Scoping – classes |
357 |
| Scoping – attributes |
614 |
| Shadow DOM |
49 |
| Unscoped |
1022 |
Initially, the Chrome data tells a pretty simple story: shadow DOM is clearly the fastest, followed by style scoping with classes, followed by style scoping with attributes, followed by unscoped CSS. So the message is simple: use Shadow DOM, but if not, then use classes instead of attributes for scoping.
I noticed something interesting with Chrome, though: the performance numbers are vastly different for these two cases:
- 1,000 components: insert 1,000 different
<style>s into the <head>
- 1,000 components: concatenate those styles into one big
<style>
As it turns out, this simple optimization greatly improves the Chrome numbers:
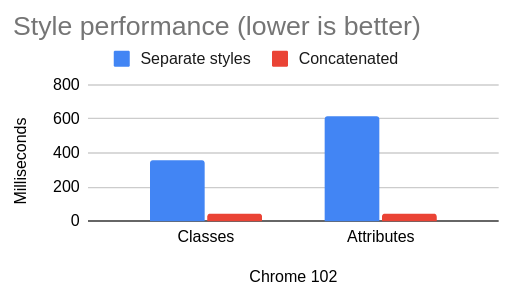
Click for table
| Scenario |
Chrome 102 – separate styles |
Chrome 102 – concatenated |
| Classes |
357 |
48 |
| Attributes |
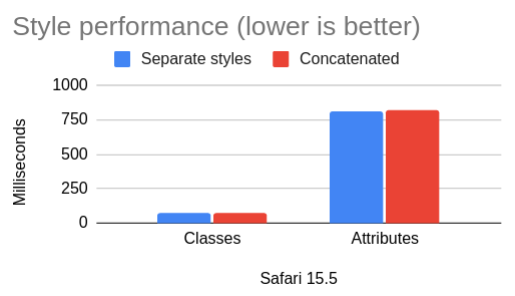
614 |
43 |
When I first saw these numbers, I was confused. I could understand this optimization in terms of reducing the cost of DOM insertions. But we’re talking about style calculation – not DOM API performance. In theory, it shouldn’t matter whether there are 1,000 stylesheets or one big stylesheet. And indeed, Firefox and Safari show no difference between the two:

Click for table
| Scenario |
Firefox 101 – separate styles |
Firefox 101 – concatenated |
| Classes |
30 |
29 |
| Attributes |
38 |
38 |

Click for table
| Scenario |
Safari 15.5 – separate styles |
Safari 15.5. – concatenated |
| Classes |
75 |
73 |
| Attributes |
812 |
820 |
This behavior was curious enough that I filed a bug on Chromium. According to the Chromium engineer who responded (thank you!), this is because of a design decision to trade off some initial performance in favor of incremental performance when stylesheets are modified or added. (My benchmark is a bit unfair to Chrome, since it only measures the initial calculation. A good idea for a future benchmark!)
This is actually a pretty interesting data point for JavaScript framework and bundler authors. It seems that, for Chromium anyway, the ideal technique is to concatenate stylesheets similarly to how JavaScript bundlers do code-splitting – i.e. trying to concatenate as much as possible, while still splitting in some cases to optimize for caching across routes. (Or you could go full inline and just put one big <style> on every page.) Keep in mind, though, that this is a peculiarity of Chromium’s current implementation, and it could go away at any moment if Chromium decides to change it.
In terms of the benchmark, though, it’s not clear to me what to do with this data. You might imagine that it’s a simple optimization for a JavaScript framework (or meta-framework) to just concatenate all the styles together, but it’s not always so straightforward. When a component is mounted, it may call getComputedStyle() on its own DOM nodes, so batching up all the style insertions until after a microtask is not really feasible. Some meta-frameworks (such as Nuxt and SvelteKit) leverage a bundler to concatenate the styles and insert them before the component is mounted, but it feels a bit unfair to depend on that for the benchmark.
To me, this is one of the core advantages of shadow DOM – you don’t have to worry if your bundler is configured correctly or if your JavaScript framework uses the right kind of style scoping. Shadow DOM is just performant, all of the time, full stop. That said, here is the Chrome comparison data with the concatenation optimization applied:

Click for table
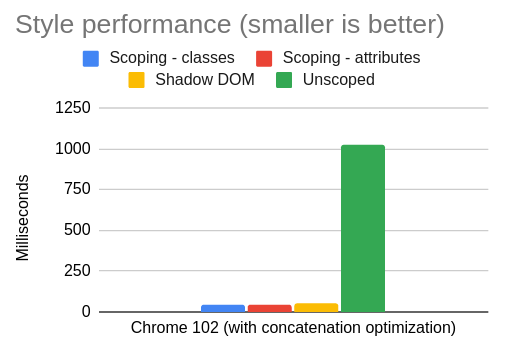
| Scenario |
Chrome 102 (with concatenation optimization) |
| Scoping – classes |
48 |
| Scoping – attributes |
43 |
| Shadow DOM |
49 |
| Unscoped |
1022 |
The first three are close enough that I think it’s fair to say that all of the three scoping methods (class, attribute, and shadow DOM) are fast enough.
Note: You may wonder if Constructable Stylesheets would have an impact here. I tried a modified version of the benchmark that uses these, and didn’t observe any difference – Chrome showed the same behavior for concatenation vs splitting. This makes sense, as none of the styles are duplicated, which is the main use case Constructable Stylesheets are designed for. I have found elsewhere, though, that Constructable Stylesheets are more performant than <style> tags in terms of DOM API performance, if not style calculation performance (e.g. see here, here, and here).
Safari
In our final tour of browsers, we arrive at Safari:
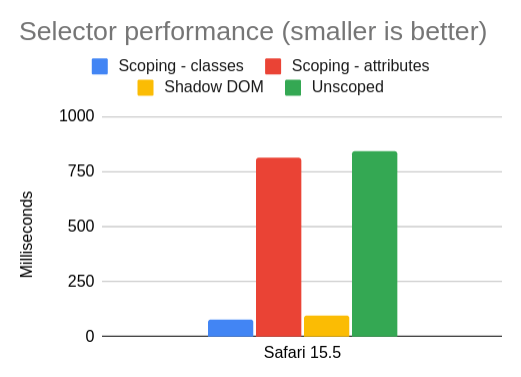
Click for table
| Scenario |
Safari 15.5 |
| Scoping – classes |
75 |
| Scoping – attributes |
812 |
| Shadow DOM |
94 |
| Unscoped |
840 |
To me, the Safari data is the easiest to reason about. Class scoping is fast, shadow DOM is fast, and unscoped CSS is slow. The one surprise is just how slow attribute selectors are compared to class selectors. Maybe WebKit has some more optimizations to do in this space – compared to Chrome and Firefox, attributes are just a much bigger performance cliff relative to classes.
This is another good example of why class scoping is superior to attribute scoping. It’s faster in all the engines, but the difference is especially stark in Safari. (Or you could use shadow DOM and not worry about it at all.)
Update: shortly after this post was published, WebKit made an optimization to attribute selectors. This seems to eliminate the perf cliff: in Safari Technology Preview 152 (Safari 16.0, WebKit 17615.1.2.3), the benchmark time for attributes drops to 77ms, which is only marginally slower than classes at 74ms (taking the median of 15 samples).
Conclusion
Performance shouldn’t be the main reason you choose a technology like scoped styles or shadow DOM. You should choose it because it fits well with your development paradigm, it works with your framework of choice, etc. Style performance usually isn’t the biggest bottleneck in a web application, although if you have a lot of CSS or a large DOM size, then you may be surprised by the amount of “Recalculate Style” costs in your next performance trace.
One can also hope that someday browsers will advance enough that style calculation becomes less of a concern. As I mentioned before, Stylo exists, it’s very good, and other browsers are free to borrow its ideas for their own engines. If every browser were as fast as Firefox, I wouldn’t have a lot of material for this blog post.

This is the same data presented in this post, but on a single chart. Just notice how much Firefox stands out from the other browsers.
Click for table
| Scenario |
Chrome 102 |
Firefox 101 |
Safari 15.5 |
| Scoping – classes |
357 |
30 |
75 |
| Scoping – attributes |
614 |
38 |
812 |
| Shadow DOM |
49 |
26 |
94 |
| Unscoped |
1022 |
114 |
840 |
| Scoping – classes – concatenated |
48 |
29 |
73 |
| Scoping – attributes – concatenated |
43 |
38 |
820 |
For those who dislike shadow DOM, there is also a burgeoning proposal in the CSS Working Group for style scoping. If this proposal were adopted, it could provide a less intrusive browser-native scoping mechanism than shadow DOM, similar to the abandoned <style scoped> proposal. I’m not a browser developer, but based on my reading of the spec, I don’t see why it couldn’t offer the same performance benefits we see with shadow DOM.
In any case, I hope this blog post was interesting, and helped shine light on an odd and somewhat under-explored space in web performance. Here is the benchmark source code and a live demo in case you’d like to poke around.
Thanks to Alex Russell and Thomas Steiner for feedback on a draft of this blog post.
Afterword – more data
Updated June 23, 2022
After writing this post, I realized I should take my own advice and automate the benchmark so that I could have more confidence in the numbers (and make it easier for others to reproduce).
So, using Tachometer, I re-ran the benchmark, taking the median of 25 samples, where each sample uses a fresh browser session. Here are the results:

Click for table
| Scenario |
Chrome 102 |
Firefox 101 |
Safari 15.5 |
| Scoping – classes |
277.1 |
45 |
80 |
| Scoping – attributes |
418.8 |
54 |
802 |
| Shadow DOM |
56.80000001 |
67 |
82 |
| Unscoped |
820.4 |
190 |
857 |
| Scoping – classes – concatenated |
44.30000001 |
42 |
80 |
| Scoping – attributes – concatenated |
44.5 |
51 |
802 |
| Unscoped – concatenated |
251.3 |
167 |
865 |
As you can see, the overall conclusion of my blog post doesn’t change, although the numbers have shifted slightly in absolute terms.
I also added “Unscoped – concatenated” as a category, because I realized that the “Unscoped” scenario would benefit from the concatenation optimization as well (in Chrome, at least). It’s interesting to see how much of the perf win is coming from concatenation, and how much is coming from scoping.
If you’d like to see the raw numbers from this benchmark, you can download them here.
Second afterword – even more data
Updated June 25, 2022
You may wonder how much Firefox’s Stylo engine is benefiting from the 10 cores in that 2021 Mac Book Pro. So I unearthed my old 2014 Mac Mini, which has only 2 cores but (surprisingly) can still run macOS Monterey. Here are the results:

Click for table
| Scenario |
Chrome 102 |
Firefox 101 |
Safari 15.5 |
| Scoping – classes |
717.4 |
107 |
187 |
| Scoping – attributes |
1069.5 |
162 |
2853 |
| Shadow DOM |
227.7 |
117 |
233 |
| Unscoped |
2674.5 |
452 |
3132 |
| Scoping – classes – concatenated |
189.3 |
104 |
188 |
| Scoping – attributes – concatenated |
191.9 |
159 |
2826 |
| Unscoped – concatenated |
865.8 |
422 |
3148 |
(Again, this is the median of 25 samples. Raw data.)
Amazingly, Firefox seems to be doing even better here relative to the other browsers. For “Unscoped,” it’s 14.4% of the Safari number (vs 22.2% on the MacBook), and 16.9% of the Chrome number (vs 23.2% on the MacBook). Whatever Stylo is doing, it’s certainly impressive.
Third update – scoping strategies
Updated October 8, 2022
I was curious about which kind of scoping strategy (e.g. Svelte-style or Vue-style) performed best in the benchmark. So I updated the benchmark to generate three “scoped selector” styles:
- Full selector: ala Svelte, every part of the selector has a class or attribute added (e.g.
div div becomes div.xyz div.xyz)
- Right-hand side (RHS): ala Vue, only the right-hand side selector is scoped with a class or attribute (e.g.
div div becomes div div.xyz)
- Tag prefix: ala Enhance, the tag name of the component is prefixed (e.g.
div div becomes my-component div div)
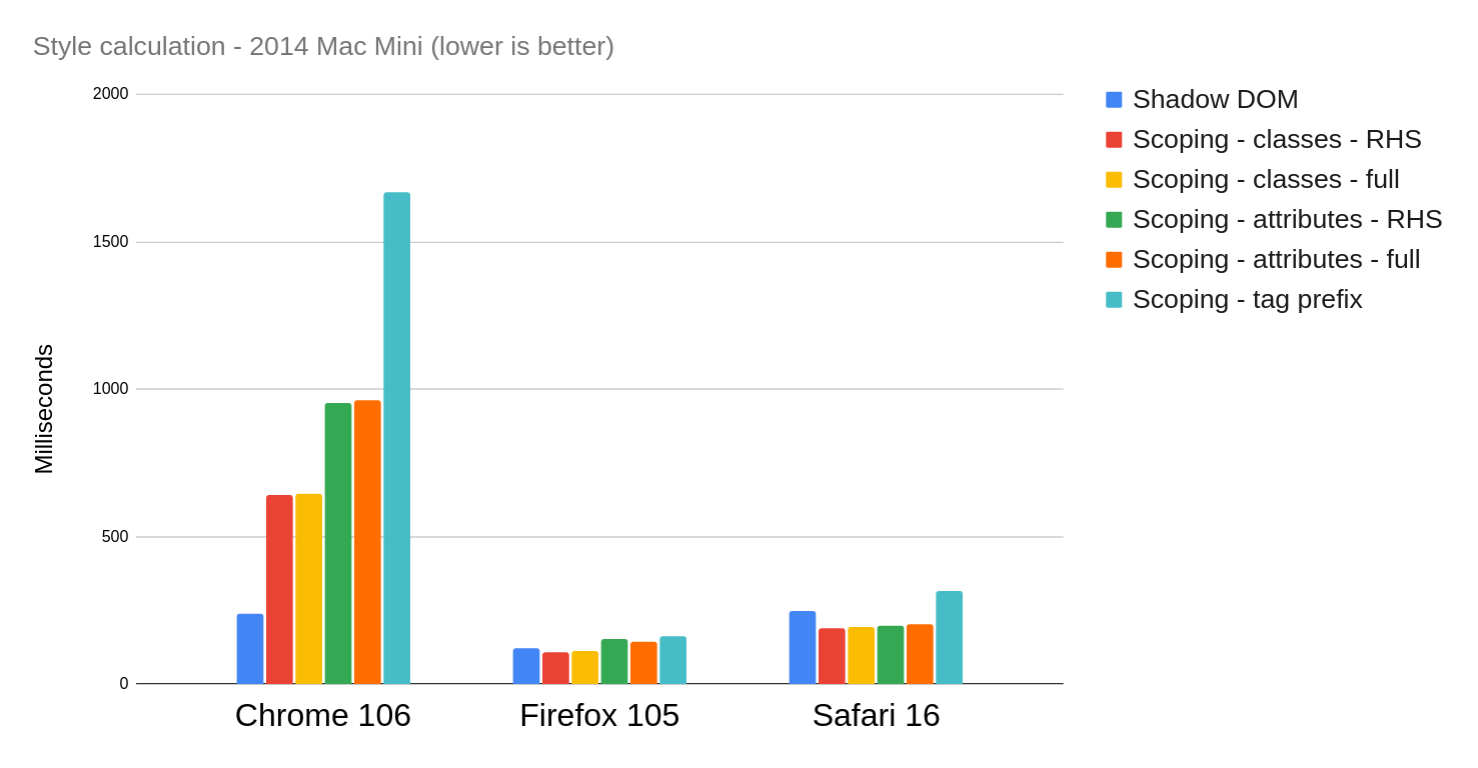
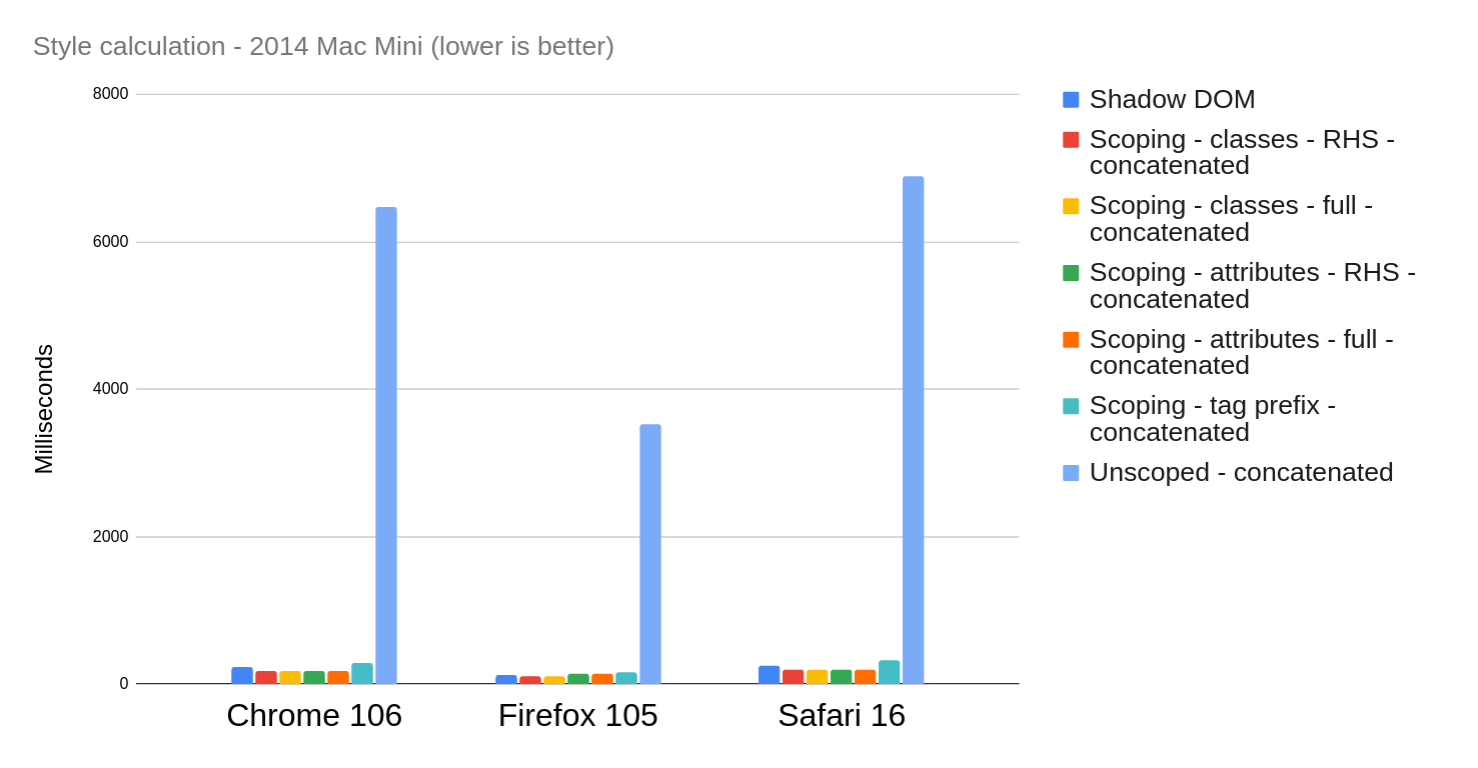
Here are the results, taking the median of 25 iterations on a 2014 Mac Mini (raw data):

Same chart with “Unscoped” removed

Table
| Scenario |
Chrome 106 |
Firefox 105 |
Safari 16 |
| Shadow DOM |
237.1 |
120 |
249 |
| Scoping – classes – RHS |
643.1 |
110 |
190 |
| Scoping – classes – full |
644.1 |
111 |
193 |
| Scoping – attributes – RHS |
954.3 |
152 |
200 |
| Scoping – attributes – full |
964 |
146 |
204 |
| Scoping – tag prefix |
1667.9 |
163 |
316 |
| Unscoped |
9767.5 |
3436 |
6829 |
Note that this version of the benchmark is slightly different from the previous one – I wanted to cover more selector styles, so I changed how the source CSS is generated to include more pseudo-classes in the ancestor position (e.g. :nth-child(2) div). This is why the “unscoped” numbers are higher than before.
My first takeaway is that Safari 16 has largely fixed the problem with attribute selectors – they are now roughly the same as class selectors. (This optimization seems to be the reason.)
In Firefox, classes are still slightly faster than attributes. I actually reached out to Emilio Cobos Álvarez about this, and he explained that, although Firefox did make an optimization to attribute selectors last year (prompted by my previous blog post), class selectors still have “a more micro-optimized code path.” To be fair, though, the difference is not enormous.
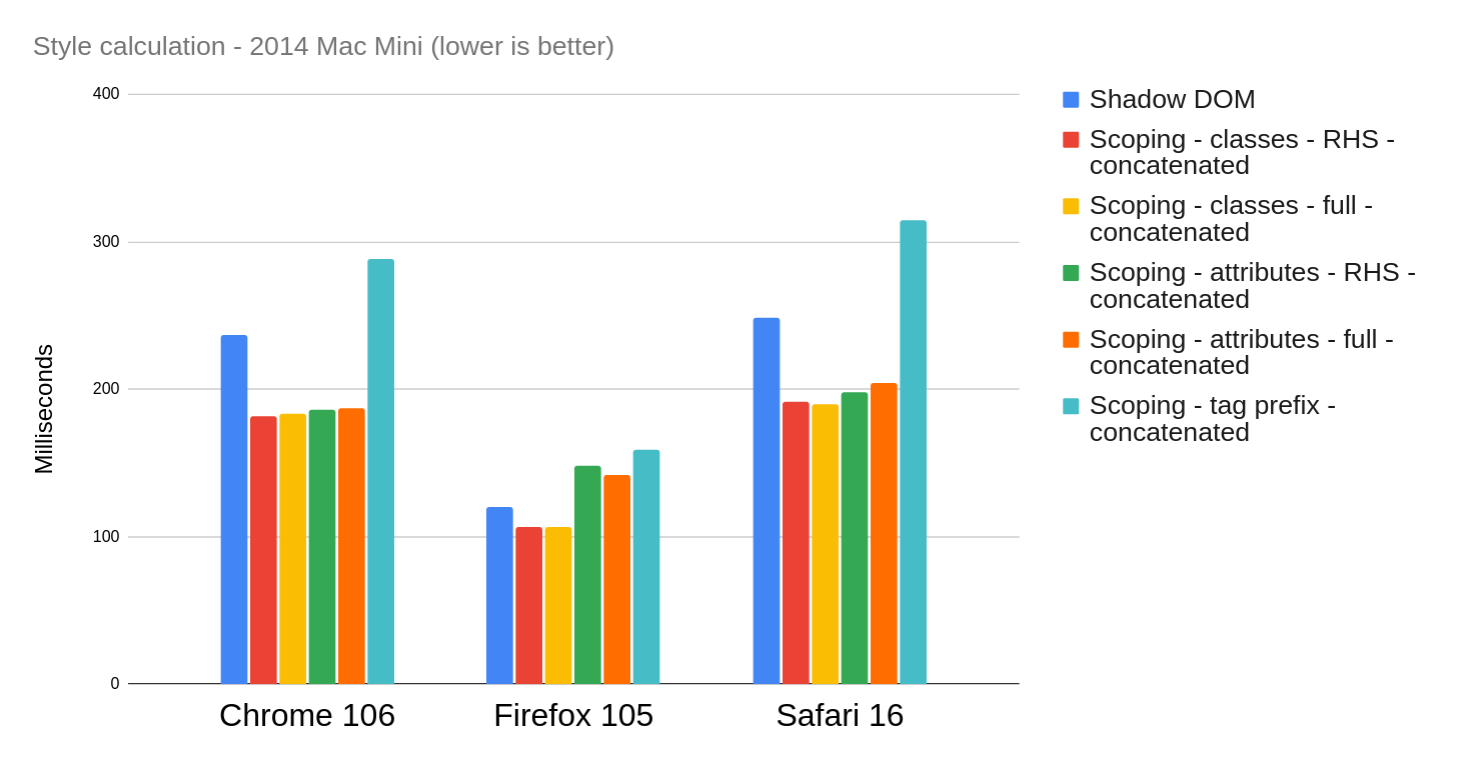
In Chrome, class selectors comfortably outperform attribute selectors, and the tag prefix is further behind. Note though, that these are the “unconcatenated” numbers – when applying the concatenation optimization, all the numbers decrease for Chrome:

Same chart with “Unscoped” removed

Table
| Scenario |
Chrome 106 |
Firefox 105 |
Safari 16 |
| Shadow DOM |
237.1 |
120 |
249 |
| Scoping – classes – RHS – concatenated |
182 |
107 |
192 |
| Scoping – classes – full – concatenated |
183.6 |
107 |
190 |
| Scoping – attributes – RHS – concatenated |
185.8 |
148 |
198 |
| Scoping – attributes – full – concatenated |
187.1 |
142 |
204 |
| Scoping – tag prefix – concatenated |
288.7 |
159 |
315 |
| Unscoped – concatenated |
6476.3 |
3526 |
6882 |
With concatenation, the difference between classes and attributes is largely erased in Chrome. As before, concatenation has little to no impact on Firefox or Safari.
In terms of which scoping strategy is fastest, overall the tag prefix seems to be the slowest, and classes are faster than attributes. Between “full” selector scoping and RHS scoping, there does not seem to be a huge difference. And overall, any scoping strategy is better than unscoped styles. (Although do keep in mind this is a microbenchmark, and some of the selectors it generates are a bit tortured and elaborate, e.g. :not(.foo) :nth-child(2):not(.bar). In a real website, the difference would probably be less pronounced.)
I’ll also note that the more work I do in this space, the less my work seems to matter – which is a good thing! Between blogging and filing bugs on browsers, I seem to have racked up a decent body count of browser optimizations. (Not that I can really take credit; all I did was nerd-snipe the relevant browser engineers.) Assuming Chromium fixes the concatenation perf cliff, there won’t be much to say except “use some kind of CSS scoping strategy; they’re all pretty good.”