Update: I made a Japanese Name Converter web site!


The Japanese Name Converter was the first Android app I ever wrote. So for me, it was kind of a “hello world” app, but in retrospect it was a doozy of a “hello world.”
The motivation for the app was pretty simple: what was something I could build to run on an Android phone that 1) lots of people would be interested in and 2) required some of my unique NLP expertise? Well, people love their own names, and if they’re geeks like me, they probably think Japanese is cool. So is there some way, I wondered, of writing a program that could automatically transliterate any English name into Japanese characters?
The task
The problem is not trivial. Japanese phonemics and phonotactics are both very restrictive, and as a result any loanword gets thoroughly mangled as it passes through the gauntlet of Japanese sound rules. Some examples are below:
beer = biiru (/bi:ru/)
heart = haato (/ha:to/)
hamburger = hanbaagaa (/hanba:ga:/)
strike (i.e. in baseball) = sutoraiku (/sutoraiku/)
volleyball = bareebooru (/bare:bo:ru/)
helicopter = herikoputaa (/herikoputa:/)
English names go through the same process:
Nolan = nooran (/no:ran/)
Michael = maikeru (/maikeru/)
Stan = sutan (/sutan/)
(Note for IPA purists: the Japanese /r/ is technically an alveolar flap, and therefore would be represented phonetically as [ɾ]. The /u/ is an unrounded [ɯ].)
Whole lotta changes going on here. To just pick out some of the highlights, notice that:
- “l” becomes “r” – Japanese, like most non-Indo-European languages, makes no distinction between the two.
- Japanese phonotactics only allow one coda – “n.” So no syllables can end on any consonant other than “n,” and no consonant clusters are allowed except for those starting with “n.” All English consonant clusters have to be epenthesized with vowels, usually “u” but sometimes “i.”
- English syllabic “r” (aka the rhotacized schwa, sometimes written [ɚ]) becomes a double vowel /a:/. Yep, they use the British, r-less pronunciation. Guess they didn’t concede everything to us Americans just because we occupied ’em.
All this is just what I’d have to do to convert the English names into romanized Japanese (roomaji). I still haven’t even mentioned having to convert this all into katakana, i.e. the syllabic alphabet Japanese uses for foreign words! Clearly I had my work cut out for me.
Initial ideas
The first solution that popped into my head was to use Transformation-Based Learning (aka the Brill tagger). My idea was that you could treat each individual letter in the English input as the observation and the corresponding sequence in the Japanese output as the class label, and then build up rules to transform them based on the context. It seemed reasonable enough. Plus, I would benefit from the fact that the output labels come from the same set as the input labels (if I used English letters, anyway). So for instance, “nolan” and “nooran” could be aligned as:
n:n
o:oo
l:r
a:a
n:n
Three of the above pairs are already correct before I even do anything. Off to a good start!
Plus, once the TBL is built, executing it would be dead simple. All of the rules just need to be applied in order, amounting to a series of string replacements. Even the limited phone hardware could handle it, unlike what I would be getting with a Markov model. Sweet! Now what?
Well, the first thing I needed was training data. After some searching, I eventually found a calligraphy web site that listed about 4,000 English-Japanese name pairs, presumably so that people could get tattoos they’d regret later. After a little wget action and some data massaging, I had my training data.
By the way, let’s take a moment to give a big hand to those unsung heroes of machine learning – the people who take the time to build up huge, painstaking corpora like these. Without them, nothing in machine learning would be possible.
First Attempt
My first attempt started out well. I began by writing a training algorithm that would generate rules (such as “convert X to Y when preceded by Z”) or (“convert A to B when followed by C”) from each of the training pairs. Each rule was structured as follows:
Antecedent: a single character in the English string
Consequence: any substring in the Japanese string (with some limit on max substring length)
Condition(s): none and/or following letter and/or preceding letter and/or is a vowel etc.
Then I calculated the gain (in terms of total Levenshtein, or edit distance improvement across the training data) for each rule. Finally, ala Brill, it was just a matter of taking the best rule at each iteration, applying it to all the strings, and continuing until some breaking point. The finished model would just be the list of rules, applied in order.
Unfortunately, this ended up failing because the rules kept mangling the input data to the point where the model was unable to recover, since I was overwriting the string with each rule. So, for instance, the first rule the model learned was “l” -> “r”. Great! That makes perfect sense, since Japanese has no “l.” However, this caused problems later on, because the model now had no way of distinguishing syllable-final “l” from “r,” which makes a huge difference in the transliteration. Ending English “er” usually becomes “aa” in Japanese (e.g. “spencer” -> “supensaa”), but ending “el” becomes “eru” (e.g. “mabel” -> “meeberu”). Since the model had overwritten all l’s with r’s, it couldn’t tell the difference. So I scrapped that idea.
Second Attempt
My Brill-based converter was lightweight, but maybe I needed to step things up a bit? I wondered if the right approach here would be to use something like a sequential classifier or HMM. Ignoring the question of whether or not that could even run on a phone (which was unlikely), I tried to run an experiment to see if it was even a feasible solution.
The first problem I ran into here was that of alignment. With the Brill-based model, I could simply generate rules where the antecedent was any character in the English input and the consequence was any substring of the Japanese input. Here, though, you’d need the output to be aligned with the input, since the HMM (or whatever) has to emit a particular class label at each observation. So, for instance, rather than just let the Brill algorithm discover on its own that “o” –> “oo” was a good rule for transliterating “nolan” to “nooran” (because it improved edit distance), I’d need to write the alignment algorithm myself before inputting it to the sequential learner.
I realized that what I was trying to do was similar to parallel corpus alignment (as in machine translation), except that in my case I was aligning letters rather than words. I tried to brush up on the machine translation literature, but it mostly went over my head. (Hey, we never covered it in my program.) So I tried a few different approaches.
I started by thinking of it like an HMM, in which case I’m trying to predict the the output Japanese sequence (j) given the input English sequence (e), where I could model the relationship like so:

And, since we’re just trying to maximize P(j|e), we can simplify this to:
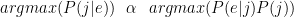
Or, in English (because I hate looking at formulas too): The probability of a Japanese string given an English string is proportional to the probability of the English string given the Japanese string multiplied by the probability of the Japanese string.
But I’m not building a full HMM – I’m just trying to figure out the partitioning of the sequence, i.e. the 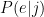
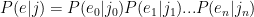
Or, in English: The probability of the English string given the Japanese string equals the product of all the probabilities of each English character given the probability of its corresponding Japanese substring.
Makes sense so far, right? All I’m doing is assuming that I can multiply the probabilities of the individual substrings together to get the total probability. This is pretty much the exact same thing you do with Naive Bayes, where you assume that all the words in a document are conditionally independent and just multiply their probabilities together.
And since I didn’t know 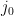
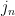
But how to model 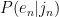
But since this formula had a tendency to favor longer Japanese substrings (because they are rarer), I leveled the playing field a bit by also multiplying the conditional probabilities of all the substrings of those substrings. (Edit: only after reading this do I realize my error was in putting count(e) in the denominator, rather than count(j). D’oh.) There! Now I finally had my beautiful converter, right?
Well, the pairings of substrings were fine – my co-occurrence heuristic seemed to find reasonable inputs and outputs. The final model, though, failed horribly. I used Minorthird to build up a Maximum Entropy Markov Model (MEMM) trained on the input 4,000 name pairs (with Minorthird’s default Feature Extractor), and the model performed even worse than the Brill one! The output just looked like random garbage, and didn’t seem to correspond to any of the letters in the input. The main problem appeared to be that there were just too many class labels, since an English letter in the input could correspond to many Japanese letters in the output.
For instance, the most extreme case I found is the name “Alex,” which transliterates to “arekkusu.” The letter “x” here corresponds to no less than five letters in the output – “kkusu.” Now imagine how many class labels there must have been, if “kkusu” was one of them. Yeah, it was ridiculous. Classification tends to get dicey when you have more than ten labels. I’d argue that even three is pushing it, since the sweet spot is really two (binary classification).
Also, it was at this point that I realized that trying to do MEMM decoding on the underpowered hardware of a phone was pretty absurd as it is. Was I really going to bundle the entire Minorthird JAR with my app and just hope it would work without throwing an OutOfMemoryError?
Third Attempt
So for my third attempt, I went back to the drawing board with the Brill tagger. But this time, I had an insight. Wasn’t my whole problem before that the training algorithm was destroying the string at each step? Why not simply add a condition to the rule that referenced the original character in the English string? For instance, even if the first rule converts all l’s to r’s, the model could still “see” the original “l,” and thus later on down the road it could discover useful rules like ‘convert “er” to “eru” when the original string was “el”, but convert “er” to “aa” when the original string was “er”‘. I immediately noticed a huge difference in the performance after adding this condition to the generated rules.
That was basically the model that led me all the way to my final, finished product. There were a few snafus – like how the training algorithm takes up an ungodly amount of memory, so I had to optimize since I was running it on my laptop with only 2GB of memory. I also only used a few rule templates and I even cut the training data from 4,000 to little over 1,000 entries, based on which names were more popular in US census data. But ultimately, I think the final model was pretty good. Below are my test results, using a test set of 47 first and last names that were not in the training data (and which I mostly borrowed from people I know).
holly -> horii (gold: hoorii) anderson -> andaason damon -> damon (gold: deemon) clinton -> kurinton lambert -> ranbaato king -> kingu maynard -> meinaado (gold: meenaado) lawson -> rooson bellow -> beroo butler -> butoraa (gold: batoraa) vorwaller -> boowaraa parker -> paakaa thompson -> somupson (gold: tompuson) potter -> pottaa hermann -> haaman stacia -> suteishia maevis -> maebisu (gold: meebisu) gerald -> jerarudo hartleben -> haatoreben hanson -> hannson (gold: hanson) brubeck -> buruubekku ferrel -> fereru poolman -> puoruman (gold: puuruman) bart -> baato smith -> sumisu larson -> raason perkowitz -> paakooitsu (gold: paakowitsu) boyd -> boido nancy -> nanshii meliha -> meria (gold: meriha) berzins -> baazinsu (gold: baazinzu) manning -> maningu sanders -> sandaasu (gold: sandaazu) durup -> duruppu (gold: durupu) thea -> sia walker -> waokaa (gold: wookaa) johnson -> jonson bardock -> barudokku (gold: baadokku) beal -> beru (gold: biiru) lovitz -> robitsu picard -> pikaado melville -> merubiru pittman -> pitman (gold: pittoman) west -> wesuto eaton -> iaton (gold: iiton) pound -> pondo eustice -> iasutisu (gold: yuusutisu) pope -> popu (gold: poopu)
Baseline (i.e. just using the English strings without applying the model at all):
Accuracy: 0.00
Total edit distance: 145
Model score:
Accuracy: 0.5833333333333334
Total edit distance: 28
(I print out “gold” and the correct answer only for the incorrect ones.)
The accuracy’s not very impressive, but as I kept tweaking the features, what I was really aiming for was low edit distance, and 28 was the lowest I was able to achieve on the test set. So this means that, even when it makes mistakes, the mistakes are usually very small, so the results are still reasonable. “Meinaado,” for instance, isn’t even a mistake – it’s just two ways of writing the same long vowel (“mei” vs. “mee”).
Anyway, many of the mistakes can be corrected by just using postprocessing heuristics (e.g. final “nn” doesn’t make any sense in Japanese, and “tm” is not a valid consontant cluster). I decided I was satisfied enough with this model to leave it as it is for now – especially given I had already spent weeks on this whole process.
This is the model that I ultimately included with the Japanese Name Converter app. The app processes any name that is not found in the built-in dictionary of 4,000 names, spits out the resulting roomaji, applies some postprocessing heuristics to obey the phonotactics of Japanese (like in the “nn” example above), converts the roomaji to katakana, and displays the result on the screen.
Of course, because it only fires when a name is outside the set of 4,000 relatively common names, the average user may actually never see the output from my TBL model. However, I like having it in the app because I think it adds something unique. I looked around at other “your name in Japanese” apps and websites, but none of them are capable of transliterating any old arbitrary string. They always give an error when the name doesn’t happen to be in their database. At least with my app, you’ll always get some transliteration, even if it’s not a perfect one.
The Japanese Name Converter is currently my third most popular Android app, after Pokédroid and Chord Reader, which I think is pretty impressive given that I never updated it. The source code is available at Github.

