Over the past year or so, I’ve learned a lot about accessibility, mostly thanks to working on Pinafore, which is a Single Page App (SPA). In this post, I’d like to share some of the highlights of what I’ve learned, in the hope that it can help others who are trying to learn more about accessibility.
One big advantage I’ve had in this area is the help of Marco Zehe, an accessibility expert who works at Mozilla and is blind himself. Marco has patiently coached me on a lot of these topics, and his comments on the Pinafore GitHub repo are a treasure trove of knowledge.
So without further ado, let’s dive in!
Misconceptions
One misconception I’ve observed in the web community is that JavaScript is somehow inherently anti-accessibility. This seems to stem from a time when screen readers did not support JavaScript particularly well, and so indeed the more JavaScript you used, the more likely things were to be inaccessible.
I’ve found, though, that most of the accessibility fixes I’ve made have actually involved writing more JavaScript, not less. So today, this rule is definitely more myth than fact. However, there are a few cases where it holds true:
divs and spans versus buttons and inputs
Here’s the best piece of accessibility advice for newbies: if something is a button, make it a <button>. If something is an input, make it an <input>. Don’t try to reinvent everything from scratch using <div>s and <span>s. This may seem obvious to more seasoned web developers, but for those who are new to accessibility, it’s worth reviewing why this is the case.
First off, for anyone who doubts that this is a thing, there was a large open-source dependency of Pinafore (and of Mastodon) that had several thousand GitHub stars, tens of thousands of weekly downloads on npm, and was composed almost entirely of <div>s and <span>s. In other words: when something should have been a <button>, it was instead a <span> with a click listener. (I’ve since fixed most of these accessibility issues, but this was the state I found it in.)
This is a real problem! People really do try to build entire interfaces out of <div>s and <span>s. Rather than chastise, though, let me analyze the problem and offer a solution.
I believe the reason people are tempted to use <div>s and <span>s is that they have minimal user agent styles, i.e. there is less you have to override in CSS. However, resetting the style on a <button> is actually pretty easy:
button {
margin: 0;
padding: 0;
border: none;
background: none;
}
99% of the time, I’ve found that this was all I needed to reset a <button> to have essentially the same style as a <div> or a <span>. For more advanced use cases, you can explore this CSS Tricks article.
In any case, the whole reason you want to use a real <button> over a <span> or a <div> is that you essentially get accessibility for free:
- For keyboard users who Tab around instead of using a mouse, a
<button>automatically gets the right focus in the right order. - When focused, you can press the Space bar on a
<button>to press it. - Screen readers announce the
<button>as a button. - Etc.
You could build all this yourself in JavaScript, but you’ll probably mess something up, and you’ll also have a bunch of extra code to maintain. So it’s best just to use the native semantic HTML elements.
SPAs must manually handle focus and scroll position
There is another case where the “JavaScript is anti-accessibility” mantra has a kernel of truth: SPA navigation. Within SPAs, it’s common for JavaScript to handle navigation between pages, i.e. by modifying the DOM and History API rather than triggering a full page load. This causes several challenges for accessibility:
- You need to manage focus yourself.
- You need to manage scroll position yourself.
For instance, let’s say I’m in my timeline, and I want to click this timestamp to see the full thread of a post:
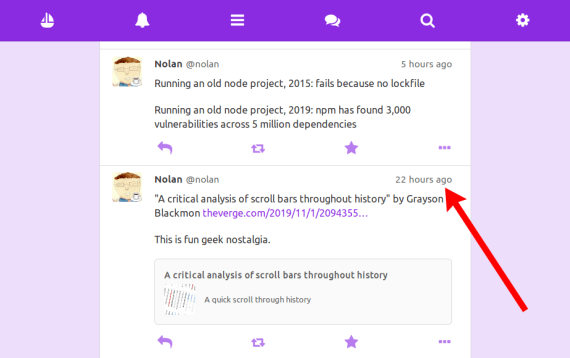
When I click the link and then press the back button, focus should return to the element I last clicked (note the purple outline):
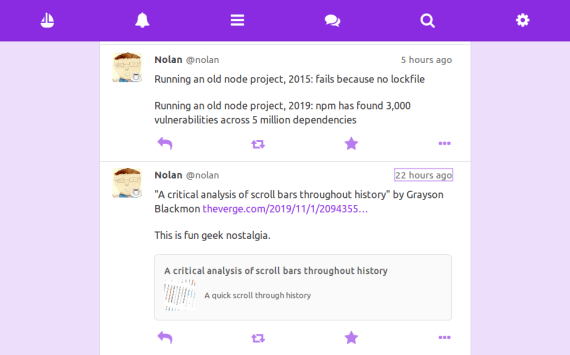
For classic server-rendered pages, most browser engines [1] give you this functionality for free. You don’t have to code anything. But in an SPA, since you’re overriding the normal navigation behavior, you have to handle the focus yourself.
This also applies to scrolling, especially in a virtual list. In the above screenshot, note that I’m scrolled down to exactly the point in the page from before I clicked. Again, this is seamless when you’re dealing with server-rendered pages, but for SPAs the responsibility is yours.
Easier integration testing
One thing I was surprised to learn is that, by making my app more accessible, I also made it easier to test. Consider the case of toggle buttons.
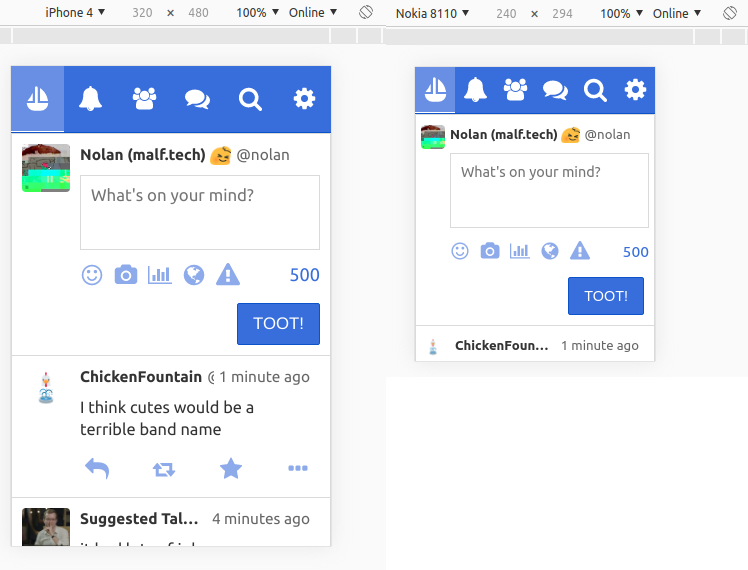
A toggle button is a button that can have two states: pressed or not pressed. For instance, in the screenshot below, the “boost” and “favorite” buttons (i.e. the circular arrow and the star) are toggle buttons, because it’s possible to boost or favorite a post, and they start off in unboosted/unfavorited states.

Visually, there are plenty of styles you can use to signal the pressed/unpressed state – for instance, I’ve opted to make the colors darker when pressed. But for the benefit of screen reader users, you’ll typically want to use a pattern like the following:
<button type="button" aria-pressed="false"> Unpressed </button> <button type="button" aria-pressed="true"> Pressed </button>
Incidentally, this makes it easier to write integration tests (e.g. using TestCafe or Cypress). Why rely on classes and styles, which might change if you redesign your app, when you can instead rely on the semantic attributes, which are guaranteed to stay the same?
I observed this pattern again and again: the more I improved accessibility, the easier things were to test. For instance:
- When using the feed pattern, I could use
aria-posinsetandaria-setsizeto confirm that the virtual list had the correct number of items and in the correct order. - For buttons without text, I could test the
aria-labelrather than the background image or something that might change if the design changed. - For hidden elements, I could use
aria-hiddento identify them. - Etc.
So make accessibility a part of your testing strategy! If something is easy for screen readers to interpret, then it’ll probably be easier for your automated tests to interpret, too. After all, screen reader users might not be able to see colors, but neither can your headless browser tests!
Subtleties with focus management
After watching this talk by Ian Forrest and playing around with KaiOS, I realized I could make some small changes to improve keyboard accessibility in my app.
As pointed out in the talk, it’s not necessarily the case that every mouse-accessible element also needs to be keyboard-accessible. If there are redundant links on the page, then you can skip them in the tabindex order, so a keyboard user won’t have to press Tab so much.
In the case of Pinafore, consider a post. There are two links that lead to the user’s profile page – the profile picture and the user name:

These two links lead to exactly the same page; they are strictly redundant. So I chose to add tabindex="-1" to the profile picture, giving keyboard users one less link to have to Tab through. Especially on a KaiOS device with a tiny d-pad, this is a nice feature!
In the above video, note that the profile picture and timestamp are skipped in the tab order because they are redundant – clicking the profile picture does the same thing as clicking the user name, and clicking the timestamp does the same thing as clicking on the entire post. (Users can also disable the “click the entire post” feature, as it may be problematic for those with motor impairments. In that case, the timestamp is re-added to the tab order.)
Interestingly, an element with tabindex="-1" can still become focused if you click it and then press the back button. But luckily, tabbing out of that element does the right thing as long as the other tabbable elements are in the proper order.
The final boss: accessible autocomplete
After implementing several accessible widgets from scratch, including the feed pattern and an image carousel (which I described in a previous post), I found that the single most complicated widget to implement correctly was autocompletion.
Originally, I had implemented this widget by following this design, which relies largely on creating an element with aria-live="assertive" which explicitly speaks every change in the widget state (e.g. “the current selected item is number 2 of 3”). This is kind of a heavy-handed solution, though, and it led to several bugs.
After toying around with a few patterns, I eventually settled on a more standard design using aria-activedescendant. Roughly, the HTML looks like this:
<textarea
id="the-textarea"
aria-describedby="the-description"
aria-owns="the-list"
aria-expanded="false"
aria-autocomplete="both"
aria-activedescendant="option-1">
</textarea>
<ul id="the-list" role="listbox">
<li
id="option-1"
role="option"
aria-label="First option (1 of 2)">
</li>
<li
id="option-2"
role="option"
aria-label="Second option (2 of 2)">
</li>
</ul>
<label for="the-textarea" class="sr-only">
What's on your mind?
</label>
<span id="the-description" class="sr-only">
When autocomplete results are available, press up or down
arrows and enter to select.
</span>
Explaining this pattern probably deserves a blog post in and of itself, but in broad strokes, what’s happening is:
- The description and label are offscreen, using styles which make it only visible to screen readers. The description explains that you can press up or down on the results and press enter to select.
aria-expandedindicates whether there are autocomplete results or not.aria-activedescendantindicates which option in the list is selected.aria-labels on the options allow me to control how it’s spoken to a screen reader, and to explicitly include text like “1 of 2” in case the screen reader doesn’t speak this information.
After extensive testing, this was more-or-less the best solution I could come up with. It works perfectly in NVDA on the latest version of Firefox, although sadly it has some minor issues in VoiceOver on Safari and NVDA on Chrome. However, since this is the standards-based solution (and doesn’t rely on aria-live="assertive" hacks), my hope is that browsers and screen readers will catch up with this implementation.
Update: I managed to get this widget working in Chrome+NVDA and Safari+VoiceOver. The fixes needed are described in this comment.
Manual and automated accessibility testing
There are a lot of automated tools that can give you good tips on improving accessibility in your web app. Some of the ones I’ve used include Lighthouse (which uses Axe under the hood), the Chrome accessibility tools, and the Firefox accessibility tools. (These tools can give you slightly different results, so I like to use multiple so that I can get second opinions!)

However, I’ve found that, especially for screen reader accessibility, there is no substitute for testing in an actual browser with an actual screen reader. It gives you the exact experience that a screen reader user would have, and it helps build empathy for what kinds of design patterns work well for voice navigation and which ones don’t. Also, sometimes screen readers have bugs or slightly differing behavior, and these are things that accessibility auditing tools can’t tell you.
If you’re just getting started, I would recommend watching Rob Dodson’s “A11ycasts” series, especially the tutorials on VoiceOver for macOS and NVDA for Windows. (Note that NVDA is usually paired with Firefox and VoiceOver is optimized for Safari. So although you can use either one with other browsers, those are the pairings that tend to be most representative of real-world usage.)
Personally I find VoiceOver to be the easiest to use from a developer’s point of view, mostly because it has a visual display of the assistive text while it’s being spoken.

NVDA can also be configured to do this, but you have to know to go into the settings and enable the “Speech Viewer” option. I would definitely recommend turning this on if you’re using NVDA for development!
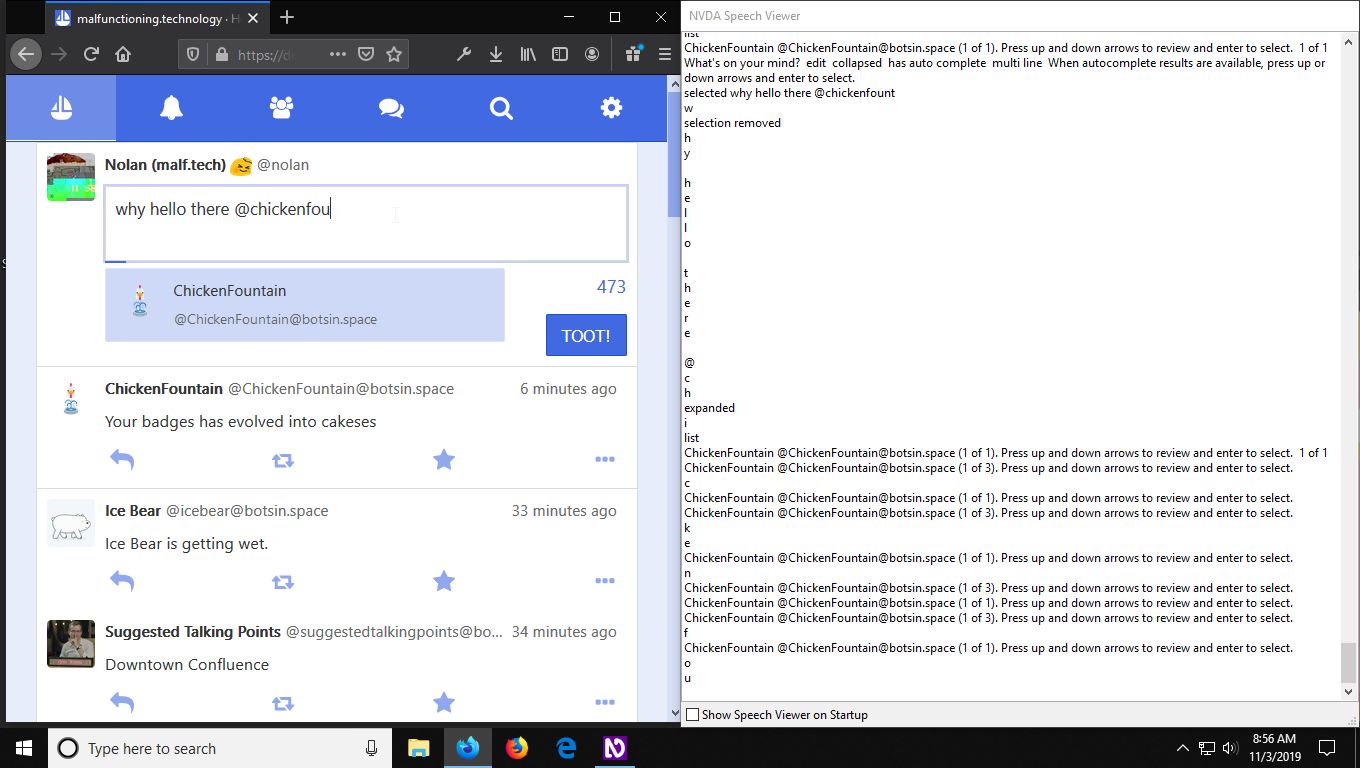
Similar to testing screen readers, it’s also a good idea to try Tabing around your app to see how comfortable it is with a keyboard. Does the focus change unexpectedly? Do you have to do a lot of unnecessary Tabing to get where you want? Are there any handy keyboard shortcuts you’d like to add?
For a lot of things in accessibility, there are no hard-and-fast rules. Like design or usability in general, sometimes you just have to experience what your users are experiencing and see where you can optimize.
Conclusion
Accessibility can be challenging, but ultimately it’s worth the effort. Working on accessibility has improved the overall usability of my app in a number of ways, leading to unforeseen benefits such as KaiOS arrow key navigation and better integration tests.
The greatest satisfaction, though, comes from users who are happy with the work I’ve done. I was beyond pleased when Marco had this to say:
“Pinafore is for now by far the most accessible way to use Mastodon. I use it on desktop as well as iOS, both iPhone & iPad, too. So thank you again for getting accessibility in right from the start and making sure the new features you add are also accessible.”
– Marco Zehe, October 21 2019
Thank you, Marco, and thanks for all your help! Hopefully this blog post will serve as a way to pay your accessibility advice forward.
Thanks to Sorin Davidoi, Thomas Wilburn, and Marco Zehe for feedback on a draft of this post.
Footnotes
1. In the course of writing this article, I was surprised to learn that, for server-rendered pages, pressing the back button restores focus to the previously-clicked element in Firefox, Safari, and Edge (EdgeHTML), but not Chrome. I found a webcompat.com bug describing the browser difference, I’ve gone ahead and filed a bug on Chrome.