2025 update: there is now a getAllRecords API in IndexedDB which resolves some of the issues described in this post. Namely, you can now query in batches in descending order, and you can fetch both keys and values in bulk. Patrick Brosset provides more details.
Recently I read James Long’s article “A future for SQL on the web”. It’s a great post, and if you haven’t read it, you should definitely go take a look!
I don’t want to comment on the specifics of the tool James created, except to say that I think it’s a truly amazing feat of engineering, and I’m excited to see where it goes in the future. But one thing in the post that caught my eye was the benchmark comparisons of IndexedDB read/write performance (compared to James’s tool, absurd-sql).
The IndexedDB benchmarks are fair enough, in that they demonstrate the idiomatic usage of IndexedDB. But in this post, I’d like to show how raw IndexedDB performance can be improved using a few tricks that are available as of IndexedDB v2 and v3:
- Pagination (v2)
- Relaxed durability (v3)
- Explicit transaction commits (v3)
Let’s go over each of these in turn.
Pagination
Years ago when I was working on PouchDB, I hit upon an IndexedDB pattern that, at the time, improved performance in Firefox and Chrome by roughly 40-50%. I’m probably not the first person to come up with this idea, but I’ll lay it out here.
In IndexedDB, a cursor is basically a way of iterating through the data in a database one-at-a-time. And that’s the core problem: one-at-a-time. Sadly, this tends to be slow, because at every step of the iteration, JavaScript can respond to a single item from the cursor and decide whether to continue or stop the iteration.
Effectively this means that there’s a back-and-forth between the JavaScript main thread and the IndexedDB engine (running off-main-thread). You can see it in this screenshot of the Chrome DevTools performance profiler:

Or in Chrome tracing, which shows a bit more detail:

Notice that each call to cursor.continue() gets its own little JavaScript task, and the tasks are separated by a bit of idle time. That’s a lot of wasted time for each item in a database!
Luckily, in IndexedDB v2, we got two new APIs to help out with this problem: getAll() and getAllKeys(). These allow you to fetch multiple items from an object store or index in a single go. They can also start from a given key range and return a given number of items, meaning that we can implement a paginated cursor:
const batchSize = 100
let keys, values, keyRange = null
function fetchMore() {
// If there could be more results, fetch them
if (keys && values && values.length === batchSize) {
// Find keys greater than the last key
keyRange = IDBKeyRange.lowerBound(keys.at(-1), true)
keys = values = undefined
next()
}
}
function next() {
store.getAllKeys(keyRange, batchSize).onsuccess = e => {
keys = e.target.result
fetchMore()
}
store.getAll(keyRange, batchSize).onsuccess = e => {
values = e.target.result
fetchMore()
}
}
next()
In the example above, we iterate through the object store, fetching 100 items at a time rather than just 1. Using a modified version of the absurd-sql benchmark, we can see that this improves performance considerably. Here are the results for the “read” benchmark in Chrome:

Click for table
DB size (columns) vs batch size (rows):
| 100 | 1000 | 10000 | 50000 | |
|---|---|---|---|---|
| 1 | 8.9 | 37.4 | 241 | 1194.2 |
| 100 | 7.3 | 34 | 145.1 | 702.8 |
| 1000 | 6.5 | 27.9 | 100.3 | 488.3 |
(Note that a batch size of 1 means a cursor, whereas 100 and 1000 use a paginated cursor.)
And here’s Firefox:
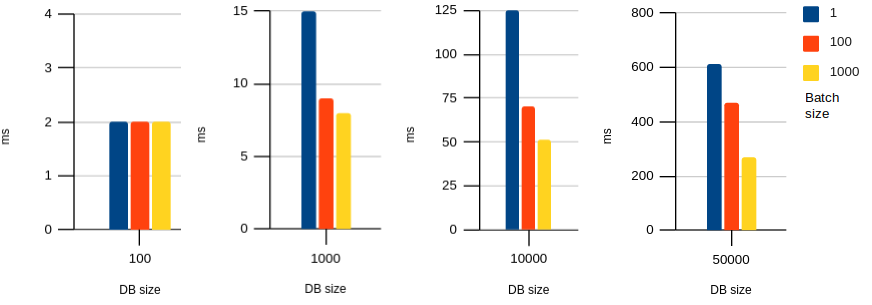
Click for table
DB size (columns) vs batch size (rows):
| 100 | 1000 | 10000 | 50000 | |
|---|---|---|---|---|
| 1 | 2 | 15 | 125 | 610 |
| 100 | 2 | 9 | 70 | 468 |
| 1000 | 2 | 8 | 51 | 271 |
And Safari:
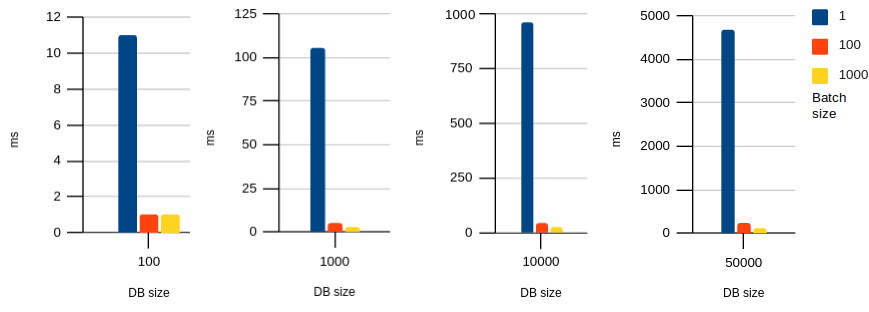
Click for table
DB size (columns) vs batch size (rows):
| 100 | 1000 | 10000 | 50000 | |
|---|---|---|---|---|
| 1 | 11 | 106 | 957 | 4673 |
| 100 | 1 | 5 | 44 | 227 |
| 1000 | 1 | 3 | 26 | 127 |
All benchmarks were run on a 2015 MacBook Pro, using Chrome 92, Firefox 91, and Safari 14.1. Tachometer was configured with 15 minimum iterations, a 1% horizon, and a 10-minute timeout. I’m reporting the median of all iterations.
As you can see, the paginated cursor is particularly effective in Safari, but it improves performance in all browser engines.
Now, this technique isn’t without its downsides. For one, you have to choose an explicit batch size, and the ideal number will depend on the size of the data and the usage patterns. You may also want to consider the downsides of overfetching – i.e. if the cursor should stop at a given value, you may end up fetching more items from the database than you really need. (Although ideally, you can use the upper bound of the key range to guard against that.)
The main downside of this technique is that it only works in one direction: you cannot build a paginated cursor in descending order. This is a flaw in the IndexedDB specification, and there are ideas to fix it, but currently it’s not possible.
Of course, instead of implementing a paginated cursor, you could also just use getAll() and getAllKeys() as-is and fetch all the data at once. This probably isn’t a great idea if the database is large, though, as you may run into memory pressure, especially on constrained devices. But it could be useful if the database is small.
getAll() and getAllKeys() both have great browser support, so this technique can be widely adopted for speeding up IndexedDB read patterns, at least in ascending order.
Relaxed durability
The paginated cursor can speed up database reads, but what about writes? In this case, we don’t have an equivalent to getAll()/getAllKeys() that we can lean on. Apparently there was some effort put into building a putAll(), but currently it’s abandoned because it didn’t actually improve write performance in Chrome.
That said, there are other ways to improve write performance. Unfortunately, none of these techniques are as effective as the paginated cursor, but they are worth investigating, so I’m reporting my results here.
The most significant way to improve write performance is with relaxed durability. This API is currently only available in Chrome, but it has also been implemented in WebKit as of Safari Technology Preview 130.
The idea behind relaxed durability is to resolve some disagreement between the browser vendors as to whether IndexedDB transactions should optimize for durability (writes succeed even in the event of a power failure or crash) or performance (writes succeed quickly, even if not fully flushed to disk).
It’s been well documented that Chrome’s IndexedDB performance is worse than Firefox’s or Safari’s, and part of the reason seems to be that Chrome defaults to a durable-by-default mode. But rather than sacrifice durability across-the-board, the Chrome team wanted to expose an explicit API for developers to decide which mode to use. (After all, only the web developer knows if IndexedDB is being used as an ephemeral cache or a store of priceless family photos.) So now we have three durability options: default, relaxed, and strict.
Using the “write” benchmark, we can test out relaxed durability in Chrome and see the improvement:
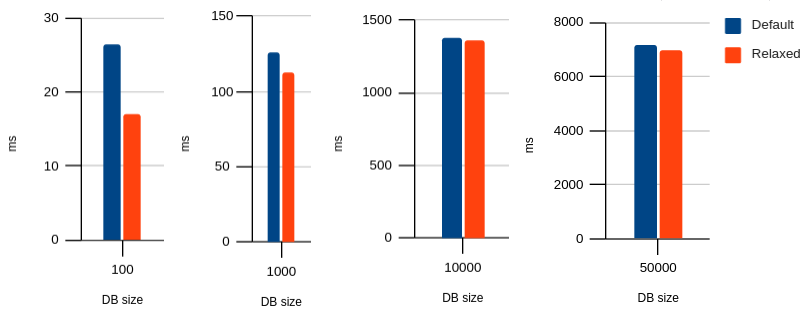
Click for table
| Durability | 100 | 1000 | 10000 | 50000 |
|---|---|---|---|---|
| Default | 26.4 | 125.9 | 1373.7 | 7171.9 |
| Relaxed | 17.1 | 112.9 | 1359.3 | 6969.8 |
As you can see, the results are not as dramatic as with the pagination technique. The effect is most visible in the smaller database sizes, and the reason turns out to be that relaxed durability is better at speeding up multiple small transactions than one big transaction.
Modifying the benchmark to do one transaction per item in the database, we can see a much clearer impact of relaxed durability:
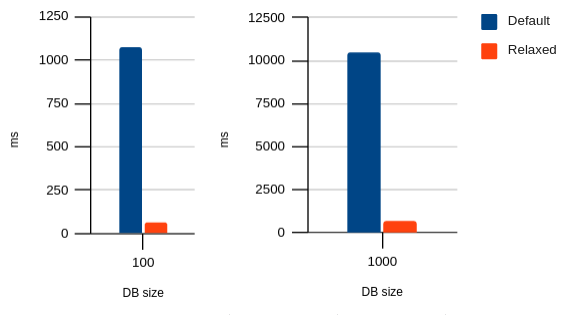
Click for table
| Durability | 100 | 1000 |
|---|---|---|
| Default | 1074.6 | 10456.2 |
| Relaxed | 65.4 | 630.7 |
(I didn’t measure the larger database sizes, because they were too slow, and the pattern is clear.)
Personally, I find this option to be nice-to-have, but underwhelming. If performance is only really improved for multiple small transactions, then usually there is a simpler solution: use fewer transactions.
It’s also underwhelming given that, even with this option enabled, Chrome is still much slower than Firefox or Safari:

Click for table
| Browser | 100 | 1000 | 10000 | 50000 |
|---|---|---|---|---|
| Chrome (default) | 26.4 | 125.9 | 1373.7 | 7171.9 |
| Chrome (relaxed) | 17.1 | 112.9 | 1359.3 | 6969.8 |
| Firefox | 8 | 53 | 436 | 1893 |
| Safari | 3 | 28 | 279 | 1359 |
That said, if you’re not storing priceless family photos in IndexedDB, I can’t see a good reason not to use relaxed durability.
Explicit transaction commits
The last technique I’ll cover is explicit transaction commits. I found it to be an even smaller performance improvement than relaxed durability, but it’s worth mentioning.
This API is available in both Chrome and Firefox, and (like relaxed durability) has also been implemented in Safari Technology Preview 130.
The idea is that, instead of allowing the transaction to auto-close based on the normal flow of the JavaScript event loop, you can explicitly call transaction.close() to signal that it’s safe to close the transaction immediately. This results in a very small performance boost because the IndexedDB engine is no longer waiting for outstanding requests to be dispatched. Here is the improvement in Chrome using the “write” benchmark:
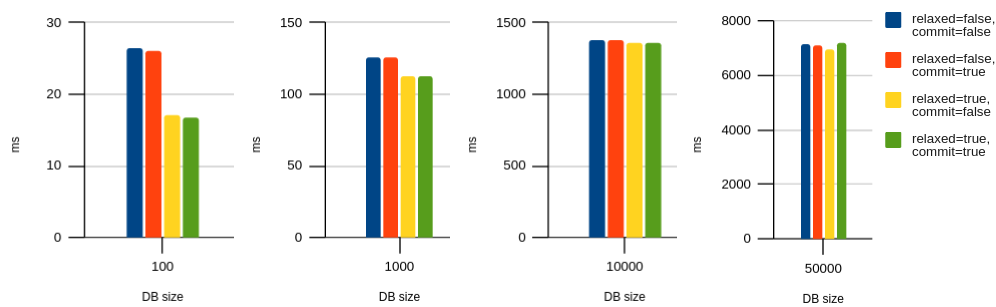
Click for table
| Relaxed / Commit | 100 | 1000 | 10000 | 50000 |
|---|---|---|---|---|
| relaxed=false, commit=false | 26.4 | 125.9 | 1373.7 | 7171.9 |
| relaxed=false, commit=true | 26 | 125.5 | 1373.9 | 7129.7 |
| relaxed=true, commit=false | 17.1 | 112.9 | 1359.3 | 6969.8 |
| relaxed=true, commit=true | 16.8 | 112.8 | 1356.2 | 7215 |
You’d really have to squint to see the improvement, and only for the smaller database sizes. This makes sense, since explicit commits can only shave a bit of time off the end of each transaction. So, like relaxed durability, it has a bigger impact on multiple small transactions than one big transaction.
The results are similarly underwhelming in Firefox:

Click for table
| Commit | 100 | 1000 | 10000 | 50000 |
|---|---|---|---|---|
| No commit | 8 | 53 | 436 | 1893 |
| Commit | 8 | 52 | 434 | 1858 |
That said, especially if you’re doing multiple small transactions, you might as well use it. Since it’s not supported in all browsers, though, you’ll probably want to use a pattern like this:
if (transaction.commit) {
transaction.commit()
}
If transaction.commit is undefined, then the transaction can just close automatically, and functionally it’s the same.
Update: Daniel Murphy points out that transaction.commit() can have bigger perf gains if the page is busy with other JavaScript tasks, which would delay the auto-closing of the transaction. This is a good point! My benchmark doesn’t measure this.
Conclusion
IndexedDB has a lot of detractors, and I think most of the criticism is justified. The IndexedDB API is awkward, it has bugs and gotchas in various browser implementations, and it’s not even particularly fast, especially compared to a full-featured, battle-hardened, industry-standard tool like SQLite. The new APIs unveiled in IndexedDB v3 don’t even move the needle much. It’s no surprise that many developers just say “forget it” and stick with localStorage, or they create elaborate solutions on top of IndexedDB, such as absurd-sql.
Perhaps I just have Stockholm syndrome from having worked with IndexedDB for so long, but I don’t find it to be so bad. The nomenclature and the APIs are a bit weird, but once you wrap your head around it, it’s a powerful tool with broad browser support – heck, it even works in Node.js via fake-indexeddb and indexeddbshim. For better or worse, IndexedDB is here to stay.
That said, I can definitely see a future where IndexedDB is not the only player in the browser storage game. We had WebSQL, and it’s long gone (even though I’m still maintaining a Node.js port!), but that hasn’t stopped people from wanting a more high-level database API in the browser, as demonstrated by tools like absurd-sql. In the future, I can imagine something like the Storage Foundation API making it more straightforward to build custom databases of top of low-level storage primitives – which is what IndexedDB was designed to do, and arguably failed at. (PouchDB, for one, makes extensive use of IndexedDB’s capabilities, but I’ve seen plenty of storage wrappers that essentially use IndexedDB as a dumb key-value store.)
I’d also like to see the browser vendors (especially Chrome) improve their IndexedDB performance. The Chrome team has said that they’re focused on read performance rather than write performance, but really, both matter. A mobile app developer can ship a prebuilt SQLite .db file in their app; in terms of quickly populating a database, there is nothing even remotely close for IndexedDB. As demonstrated above, cursor performance is also not great
For those web developers sticking it out with IndexedDB, though, I hope I’ve made a case that it’s not completely a lost cause, and that its performance can be improved. Who knows: maybe the browser vendors still have some tricks up their sleeves, especially if we web developers keep complaining about IndexedDB performance. It’ll be interesting to watch this space evolve and to see how both IndexedDB and its alternatives improve over the years.


Posted by nevf on August 24, 2021 at 12:34 AM
Thanks for putting in the effort for this detailed and informative article. I’d already read the absurd-sql article. That said I’m curious to know what types of apps are suffering that much from IndexedDb performance. I would have thought most Browser based apps don’t have onerous db requirements and would therefore work just fine as is.
That said it would be wonderful to have something better than IndexedDb.
Posted by Nolan Lawson on August 24, 2021 at 6:32 AM
I think James put it best in the article when he said that an order of magnitude difference in speed changes the kind of apps you’d even think of writing.
Just off the top of my head, I recall someone building a companion app for a trading card game (think “Magic: The Gathering”) and having performance problems with IndexedDB. There’s a lot of upfront data to load before the app becomes useful, and then you’d ideally like to have sophisticated querying capabilities so that people can quickly search using a variety of criteria. (Full-text search would be nice in this case!)
Apps with similar problems would be Pokémon companion apps (load all the Pokémon data, then find all Water-types with a high base Attack, etc.), Star Wars encyclopedia apps, recipe apps, etc. Anything where there’s a large amount of data that you want available offline.
Posted by Adriana Jara Salazar (@tropicadri) on September 2, 2021 at 5:37 PM
You mentioned the durability API is only available for Chrome and Safari’s Technology Review, I think the reason for that is that ‘relaxed’ is the default behavior for durability for Firefox: https://developer.mozilla.org/en-US/docs/Web/API/IDBTransaction#firefox_durability_guarantees
Posted by Nolan Lawson on September 3, 2021 at 10:48 AM
Correct, yeah. Assuming Firefox implements durability, I imagine they will keep
relaxedas the default, and addstrictas a new option. I also imagine they will get rid of the non-standard, Firefox-onlyreadwriteflushmode.Posted by Jaison Francisco on January 4, 2023 at 11:06 AM
IndexedDB is a go-to solution for very large objects that you want to cache such as images which is what we did. I will use IndexedDB as a simple but very powerful caching solution and would not mind using Redis. I will do IndexedDB combined with RabbitMQ for PWA and near real-time web app.