I’ve avoided writing this post for a long time, partly because I try to avoid controversial topics these days, and partly because I was waiting to make my mind up about the current, all-consuming, conversation-dominating topic of generative AI. But Steve Yegge’s “Revenge of the junior developer” awakened something in me, so let’s go for it.
I don’t come to AI from nowhere. Longtime readers may be surprised to learn that I have a master’s in computational linguistics, i.e. I studied this kind of stuff 20-odd years ago. In fact, two of the authors of the famous “stochastic parrot” paper were folks I knew at the time – Emily Bender was one of my professors, and Margaret Mitchell was my lab partner in one of our toughest classes (sorry my Python sucked at the time, Meg).
That said, I got bored of working in AI after grad school, and quickly switched to general coding. I just found that “feature engineering” (which is what we called training models at the time) was not really my jam. I much preferred to put on some good coding tunes, crank up the IDE, and bust out code all day. Plus, I had developed a dim view of natural-language processing technologies largely informed by my background in (non-computational) linguistics as an undergrad.
In linguistics, we were taught that the human mind is a wondrous thing, and that Chomsky had conclusively shown that humans have a natural language instinct. The job of the linguist is to uncover the hidden rules in the human mind that govern things like syntax, semantics, and phonology (i.e. why the “s” in “beds” is pronounced like a “z” unlike in “bets,” due to the voicing of the final consonant).
Then when I switched to computational linguistics, suddenly the overriding sensation I got was that everything was actually about number-crunching, and in fact you could throw all your linguistics textbooks in the trash and just let gobs of training data and statistics do the job for you. “Every time I fire a linguist, the performance goes up,” as a famous computational linguist said.
I found this perspective belittling and insulting to the human mind, and more importantly, it didn’t really seem to work. Natural-language processing technology seemed stuck at the level of support vector machines and conditional random fields, hardly better than the Markov models in your iPhone 2’s autocomplete. So I got bored and disillusioned and left the field of AI.
Boy, that AI thing sure came back with a vengeance, didn’t it?
Still skeptical
That said, while everybody else was either reacting with horror or delight at the tidal wave of gen-AI hype, I maintained my skepticism. At the end of the day, all of this technology was still just number-crunching – brute force trying to approximate the hidden logic that Chomsky had discovered. I acknowledged that there was some room for statistics – Peter Norvig’s essay mentioning the story of an Englishman ordering an “ale” and getting served an “eel” due to the Great Vowel Shift still sticks in my brain – but overall I doubted that mere stats could ever approach anything close to human intelligence.
Today, though, philosophical questions of what AI says about human cognition seem beside the point – these things can get stuff done. Especially in the field of coding (my cherished refuge from computational linguistics), AIs now dominate: every IDE assumes I want AI autocomplete by default, and I actively have to hunt around in the settings to turn it off.
And for several years, that’s what I’ve been doing: studiously avoiding generative AI. Not just because I doubted how close to “AGI” these things actually were, but also because I just found them annoying. I’m a fast typist, and I know JavaScript like the back of my hand, so the last thing I want is some overeager junior coder grabbing my keyboard to mess with the flow of my typing. Every inline-coding AI assistant I’ve tried made me want to gnash my teeth together – suddenly instead of writing code, I’m being asked to constantly read code (which as everyone knows, is less fun). And plus, the suggestions were rarely good enough to justify the aggravation. So I abstained.
Later I read Baldur Bjarnason’s excellent book The Intelligence Illusion, and this further hardened me against generative AI. Why use a technology that 1) dumbs down the human using it, 2) generates hard-to-spot bugs, and 3) doesn’t really make you much more productive anyway, when you consider the extra time reading, reviewing, and correcting its output? So I put in my earbuds and kept coding.
Meanwhile, as I was blissfully coding away like it was ~2020, I looked outside my window and suddenly realized that the tidal wave was approaching. It was 2025, and I was (seemingly) the last developer on the planet not using gen-AI in their regular workflow.
Opening up
I try to keep an open mind about things. If you’ve read this blog for a while, you know that I’ve sometimes espoused opinions that I later completely backtracked on – my post from 10 years ago about progressive enhancement is a good example, because I’ve almost completely swung over to the progressive enhancement side of things since then. My more recent “Why I’m skeptical of rewriting JavaScript tools in ‘faster’ languages” also seems destined to age like fine milk. Maybe I’m relieved I didn’t write a big bombastic takedown of generative AI a few years ago, because hoo boy.
I started using Claude and Claude Code a bit in my regular workflow. I’ll skip the suspense and just say that the tool is way more capable than I would ever have expected. The way I can use it to interrogate a large codebase, or generate unit tests, or even “refactor every callsite to use such-and-such pattern” is utterly gobsmacking. It also nearly replaces StackOverflow, in the sense of “it can give me answers that I’m highly skeptical of,” i.e. it’s not that different from StackOverflow, but boy is it faster.
Here’s the main problem I’ve found with generative AI, and with “vibe coding” in general: it completely sucks out the joy of software development for me.
Imagine you’re a Studio Ghibli artist. You’ve spent years perfecting your craft, you love the feeling of the brush/pencil in your hand, and your life’s joy is to make beautiful artwork to share with the world. And then someone tells you gen-AI can just spit out My Neighbor Totoro for you. Would you feel grateful? Would you rush to drop your art supplies and jump head-first into the role of AI babysitter?
This is how I feel using gen-AI: like a babysitter. It spits out reams of code, I read through it and try to spot the bugs, and then we repeat. Although of course, as Cory Doctorow points out, the temptation is to not even try to spot the bugs, and instead just let your eyes glaze over and let the machine do the thinking for you – the full dream of vibe coding.
I do believe that this is the end state of this kind of development: “giving into the vibes,” not even trying to use your feeble primate brain to understand the code that the AI is barfing out, and instead to let other barf-generating “agents” evaluate its output for you. I’ll accept that maybe, maybe, if you have the right orchestra of agents that you’re conducting, then maybe you can cut down on the bugs, hallucinations, and repetitive boilerplate that gen-AI seems prone to. But whatever you’re doing at that point, it’s not software development, at least not the kind that I’ve known for the past ~20 years.
Conclusion
I don’t have a conclusion. Really, that’s my current state: ambivalence. I acknowledge that these tools are incredibly powerful, I’ve even started incorporating them into my work in certain limited ways (low-stakes code like POCs and unit tests seem like an ideal use case), but I absolutely hate them. I hate the way they’ve taken over the software industry, I hate how they make me feel while I’m using them, and I hate the human-intelligence-insulting postulation that a glorified Excel spreadsheet can do what I can but better.
In one of his podcasts, Ezra Klein said that he thinks the “message” of generative AI (in the McLuhan sense) is this: “You are derivative.” In other words: all your creativity, all your “craft,” all of that intense emotional spark inside of you that drives you to dance, to sing, to paint, to write, or to code, can be replicated by the robot equivalent of 1,000 monkeys typing at 1,000 typewriters. Even if it’s true, it’s a pretty dim view of humanity and a miserable message to keep pounding into your brain during 8 hours of daily software development.
So this is where I’ve landed: I’m using generative AI, probably just “dipping my toes in” compared to what maximalists like Steve Yegge promote, but even that little bit has made me feel less excited than defeated. I am defeated in the sense that I can’t argue strongly against using these tools (they bust out unit tests way faster than I can, and can I really say that I was ever lovingly-crafting my unit tests?), and I’m defeated in the sense that I can no longer confidently assert that brute-force statistics can never approach the ineffable beauty of the human mind that Chomsky described. (If they can’t, they’re sure doing a good imitation of it.)
I’m also defeated in the sense that this very blog post is just more food for the AI god. Everything I’ve ever written on the internet (including here and on GitHub) has been eagerly gobbled up into the giant AI katamari and is being used to happily undermine me and my fellow bloggers and programmers. (If you ask Claude to generate a “blog post title in the style of Nolan Lawson,” it can actually do a pretty decent job of mimicking my shtick.) The fact that I wrote this entire post without the aid of generative AI is cold comfort – nobody cares, and likely few have gotten to the end of this diatribe anyway other than the robots.
So there’s my overwhelming feeling at the end of this post: ambivalence. I feel besieged and horrified by what gen-AI has wrought on my industry, but I can no longer keep my ears plugged while the tsunami roars outside. Maybe, like a lot of other middle-aged professionals suddenly finding their careers upended at the peak of their creative power, I will have to adapt or face replacement. Or maybe my best bet is to continue to zig while others are zagging, and to try to keep my coding skills sharp while everyone else is “vibe coding” a monstrosity that I will have to debug when it crashes in production someday.
I honestly don’t know, and I find that terrifying. But there is some comfort in the fact that I don’t think anyone else knows what’s going to happen either.


 (by Bayes’ Law)
(by Bayes’ Law)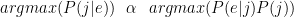
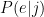 part. So I modeled that as:
part. So I modeled that as: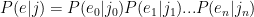
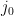 through
through 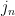 (i.e. the Japanese substring partitionings, e.g n|oo|r|a|n), my task boiled down to just generating every possible partitioning, calculating the probability for each one, and then taking the max.
(i.e. the Japanese substring partitionings, e.g n|oo|r|a|n), my task boiled down to just generating every possible partitioning, calculating the probability for each one, and then taking the max.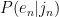 , i.e. the probability of an English letter given a Japanese substring? Co-occurrence counts seemed like the most intuitive choice here – just answering the question “how likely am I to see this English character, given the Japanese substring I’m aligning it with?” Then I could just take the product of all of those probabilities. So, for instance, in the case of “nolan” -> “nooran”, the ideal partitioning would be n|oo|r|a|n, and to figure that out I would calculate count(n,n)/count(n) * count(o,oo)/count(o) * count(l,r)/count(l) * count(a,a)/count(a) * count(n,n)/count(n), which should be the highest-scoring partitioning for that pair.
, i.e. the probability of an English letter given a Japanese substring? Co-occurrence counts seemed like the most intuitive choice here – just answering the question “how likely am I to see this English character, given the Japanese substring I’m aligning it with?” Then I could just take the product of all of those probabilities. So, for instance, in the case of “nolan” -> “nooran”, the ideal partitioning would be n|oo|r|a|n, and to figure that out I would calculate count(n,n)/count(n) * count(o,oo)/count(o) * count(l,r)/count(l) * count(a,a)/count(a) * count(n,n)/count(n), which should be the highest-scoring partitioning for that pair.
