So, you’ve found a bug in an open-source project. First off: don’t panic! This is perfectly normal. Software is written by humans, and humans make mistakes.
You might also be thinking to yourself, “Gee, I’d love to fix this bug.” I mean, who wouldn’t want to be the hero who swoops in and fixes a project used by thousands, if not millions, of people? You’d feel the warm glow of knowing you gave back to the open-source community, and plus it’s a nice notch in the belt of your Github résumé. [1]

A typical open-source bug.
For new coders, however, the idea of contributing to an open-source project can be intimidating. One of my friends, who is currently learning JavaScript from online tutorials, told me she found Github’s UI “bewildering.”
There’s also the social aspect: “Will the project maintainer accept my pull request?” “What if they criticize or dismiss me?” These are legitimate concerns to early coders, who may be self-conscious of the perceived gap between their own knowledge and that of the experts.
There’s no need to be timid, though – open-source folks love to get pull requests from newcomers! Recent efforts like First Timers Only and Your First PR have shown that, given enough of a helping hand, anyone can contribute to an open-source project.
The purpose of this blog post is a bit different. Rather than give detailed instructions for a particular bug in a particular project, I’d like to explain how I go about fixing any bug in any project. To illustrate my problem-solving process, I’ll use the example of a recent bug in the “buffer” module, which I solved in about 1 hour, despite having almost no prior experience with the project.
If I can fix a bug in an unfamiliar project, so can you!
Setting the stage
“buffer” is a JavaScript implementation of the Node.js Buffer API for the browser. It allows you to use Node.js modules that depend on the Buffer object even in the browser, where that API doesn’t exist. (Instead, browsers have other APIs for working with binary data, like Uint8Array and ArrayBuffer.)
It might seem like a weird esoteric library, but in fact “buffer” is downloaded nearly 2 million times per month, since it is a core dependency of both Browserify and Webpack. But despite being such a high-profile project, I noticed an issue that had been languishing, unresolved, for over three months.
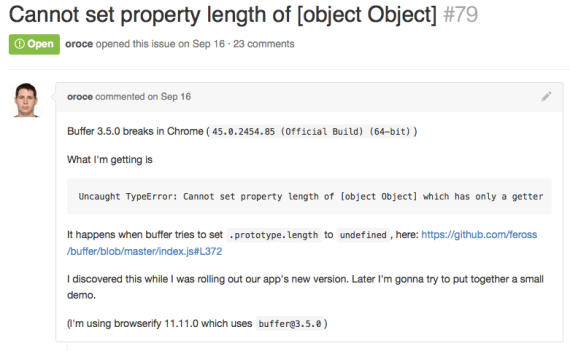
This bug was opened in September, but was still open three months later.
This issue is no minor glitch, either – it’s a showstopper that causes “buffer” to fail entirely on certain browsers (notably Chrome 43+) and in certain build setups (notably with Babel). Many people hopped onto the thread to confirm the issue (“+1”, “same here,” etc.), and a few offered workarounds using project-specific Webpack configuration. But nobody fixed it.
I decided to take a crack at this bug, because at first glance it seemed easier than everybody was making it out to be. Also, I thought it would be instructive to fix a bug in an unfamiliar codebase and document how I went about solving it.
Note: to be fair, I have contributed to “buffer” before, but these were very minor pull requests, and I still consider myself pretty inexperienced with the project. In taking up this bug, I basically had to start from scratch, to jog my memory about how the project works. [2]
Step 1: download the code
Before I could investigate the bug, I needed to be sure I could build the code myself and run the tests. This is an important step, because it confirms that the project’s tests work on my machine, as written, with my current setup.
For instance: am I using the correct version of Node for this project? The correct version of npm? Is there a global dependency (such as a linter or test runner) that I need to install? Does it work on Mac, or only on Linux or Windows? If you try to fix a bug before establishing that the code works on your machine as-is, you can end up going down a rabbit hole before you even start.
Note: the following steps are JavaScript-specific, but they can also be applied to other languages. It helps to know the conventions for your particular language, such as the typical package manager, linter, and test runner.
First, I cloned the code. You can usually find the Git URL at the top of the project, and HTTPS is recommended unless you have committer rights:

Once I had the URL, I went to my terminal (iTerm 2 in my case), and I typed:
git clone https://github.com/feross/buffer.git cd buffer
After this, I had the code on my machine, representing the master branch of the remote Git repository.
Step 2: run the tests
Once I had the code, I needed to figure out how to run the tests. Usually this information is provided in the README.md, but in this case, I searched for the word “test” and didn’t find anything. I also checked for a CONTRIBUTING.md (a document that gives instructions for contributors), but this project didn’t have one.
This is one of those cases where knowledge of the language and ecosystem can be helpful. I happen to know that most JavaScript projects are distributed with npm and can be installed and tested using:
npm install npm test
Unfortunately, in this case, the above steps completed with an error:
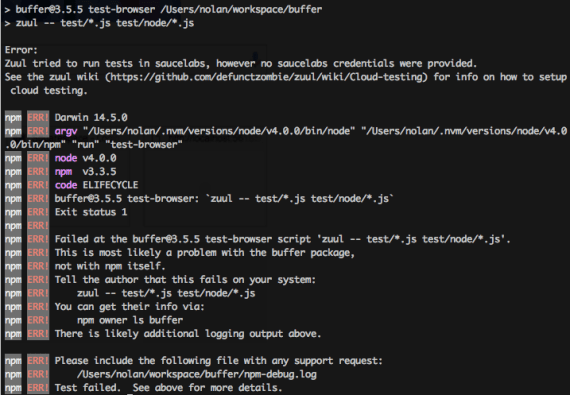
However, I noticed the most important part of the error message, which was:
Error: Zuul tried to run tests in saucelabs, however no saucelabs credentials were provided.
From reading this, I understood that this project was using Zuul and Saucelabs to run automated browser tests. Saucelabs is a remote browser-testing service, and I didn’t have my Saucelabs username or password declared as environment variables, so the tests didn’t run.
Furthermore, I didn’t really want to use Saucelabs in this case. I just wanted to test on my own machine, in my own browser. So I needed to figure out how to do that.
Luckily, in most JavaScript projects, you can just snoop around the package.json file and see what other commands are in the "scripts" section. In this case, I looked in the package.json and saw:
...
"scripts": {
"test": "standard && node ./bin/test.js",
"test-browser": "zuul -- test/*.js test/node/*.js",
"test-browser-local": "zuul --local -- test/*.js test/node/*.js",
...
Aha! test-browser-local. That sounds promising!
So I ran:
npm run test-browser-local
And this time, I got the output:
open the following url in a browser: http://localhost:62466/__zuul
Opening this URL in Chrome, I saw a nice UI where all the tests passed:

Yay! Success! At this point, I was confident that I could build and test the code on my own machine.
Note: if you’re thinking to yourself, “Wow, you shouldn’t have to do all that detective work just to test a project,” then you’re right! So I also took the time to open a pull request to document the testing procedure. This is one of the most valuable things you can do as a new contributor to a project, because seasoned contributors may be so accustomed to their workflow that they forget to include basic instructions for newbies.
Step 3: find a failing test
Next, we want to find a failing test, to confirm that we have reproduced the issue. (This is a core part of test-driven development, which is vital for many open-source projects.)
In this case, I had to read through the Github thread to try to figure out the source of the problem. Based on the discussion, it seemed that some combinations of tools (notably Babel and Webpack) might force a JavaScript module to run in strict mode. However, “buffer” is apparently not written in strict mode, so it fails in Chrome 43+ due to that browser’s interpretation of strict mode.
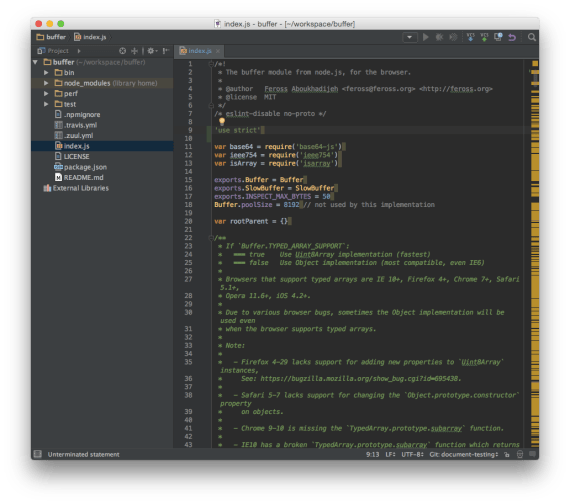
Based on this information, I figured I could reproduce the issue by simply adding 'use strict' to the top of the index.js file. (I knew index.js was the source file by checking the "main" field in package.json. But it’s also kinda obvious, because it’s the only top-level JavaScript file in this project.)
So I added 'use strict' to the top of index.js:
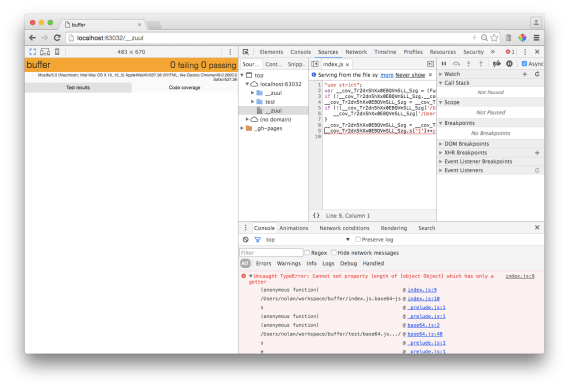
And lo and behold, when I refreshed the Zuul test page, I immediately saw the bug that everyone was talking about:

(Notice that the tests didn’t even manage to run. The page is yellow rather than green, and it says “0 failing, 0 passing.”)
At this point, I had successfully reproduced the bug, using the project’s own test suite. This is an invaluable step, for a few reasons:
- Even if you can’t solve the bug, you can open a pull request with just the failing test. This helps bypass a lot of lengthy discussion about how to reproduce the bug.
- And if you can solve the bug, then this gives you a way to prove that you’ve fixed it.
Here I just got lucky, because the existing tests were enough to suss out the problem. Sometimes, though, you may need to modify the tests yourself to reproduce the issue. In those cases, my workflow is usually:
- Try to break an existing test, e.g. by changing an
assertTrue()toassertFalse(), then confirm that you see the test failing. (Believe me, this is a good sanity check!) - Next, copy-paste a test that looks similar to the one you want to write. Then modify that new test until it fails.
For this particular bug, though, I already had a failing test. So I could move on to the next step.
Step 4: fix the bug
Unfortunately, the stacktrace didn’t provide a lot of guidance. And even the line numbers were messed up, because Zuul seems to mangle the code when it transpiles it. So that didn’t help.
At this point, I was a bit puzzled. But I tried to think logically: it says we’re setting a property called length on an object that only supports a getter, not a setter. So is there any place where we do something like foo.length = bar? I tried searching the code for instances of .length =:
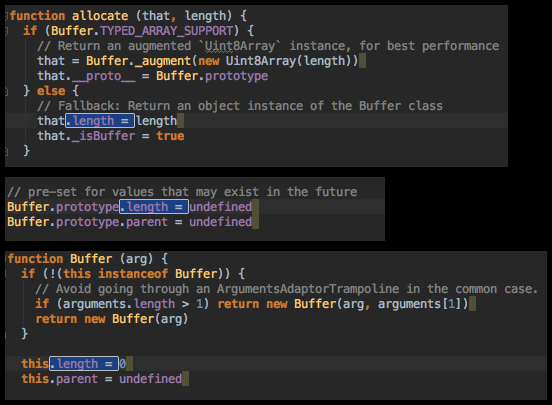
I found three places where .length is set. The most interesting is the first one, because it’s wrapped in a conditional if/else on Buffer.TYPED_ARRAY_SUPPORT. I have no idea what TYPED_ARRAY_SUPPORT is, but it immediately set off alarm bells for me that the .length assignment was guarded in one case, but not in the other two.
Trying to figure out what this TYPED_ARRAY_SUPPORT thing is, I came across this line of code:
if (Buffer.TYPED_ARRAY_SUPPORT) {
Buffer.prototype.__proto__ = Uint8Array.prototype
Buffer.__proto__ = Uint8Array
}
Aha, so when we have TYPED_ARRAY_SUPPORT (whatever that is), we set the prototype of the Buffer object (which is what index.js exports) to be the same as the prototype of the built-in Uint8Array. Hmm, and then in some cases, we’re setting that same prototype.length ourselves. Could it be that Chrome is blocking us from modifying the prototype of the built-in object, in strict mode? A theory for the bug was starting to materialize.
So I did a very simple fix: I took the two cases where length was being set, and I wrapped them both in checks for if (!Buffer.TYPED_ARRAY_SUPPORT):
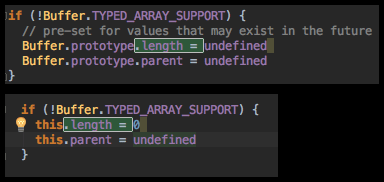
(I also wrapped the .parent assignment, even though I wasn’t sure what it was doing, because it seemed related to the .length assignment.)
Then I refreshed the browser tests, and suddenly all 84 tests were passing! So apparently, that did the trick.
Step 5: open a pull request
At this point, it’s tempting to pat yourself on the back and declare victory. However, with most browser libraries, you can only be sure that your fix works if you test it against a wide variety of browsers. In this case, the Buffer.TYPED_ARRAY_SUPPORT fix seemed to be working for Chrome, but what about other browsers?
Rather than run the tests myself against every browser installed on my laptop (which would exclude browsers like IE and Android, because I’m on a Mac), a simpler trick is to just open a pull request on the project. Most well-run open-source projects have automated tests that run on every commit, including pull requests. This is an invaluable part of the pull request process, because it gives maintainers the peace of mind to know that the patch doesn’t break any tests.
I could tell that “buffer” was indeed using automated tests against many browsers, because I saw the Saucelabs badge in the project README:
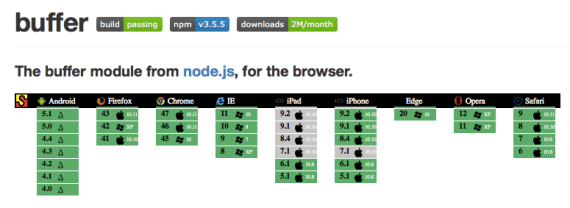
The Saucelabs badge shows the current state of the tests across various browsers.
Before opening my pull request, though, I also needed to check that my code conformed to the project style, which in this case is the somewhat presumptuously-named Standard. Personally I don’t much like Standard (semicolons for life!), but this isn’t my project, so I follow the age-old advice of “when in Rome, do as the Romans do.”
To check if your code conforms to Standard style, you can simply run:
npm install -g standard && standard
This passed, so I knew I was following the style guide of the project.
Next, to commit the fix, I created a separate Git branch. I called it 79, because that’s the issue number, and it’s a habit of mine to just name branches after the issue:
git checkout -b 79 git add index.js git commit -m 'Proper strict mode support. Fixes #79'
Then, I forked the project and submitted a pull request using hub, which is a convenient git wrapper with some Github-specific tools:
hub fork git push nolanlawson 79 hub pull-request
At this point, hub will create the pull request and print out a URL so you can view it in a browser. After waiting a bit for the tests to complete, I saw that I had a green checkmark – the tests passed in all browsers!
If the tests failed and you’re unsure why, you can always click the “Show all checks” link, then click “Details” for any failed test:

In this case, I could see that the tests were run by Travis CI, and I could also see the full log output for the tests:
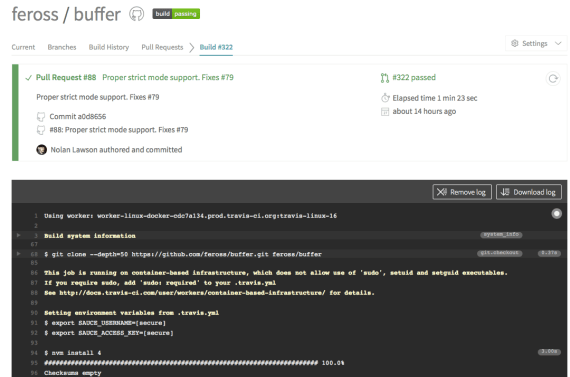
Reassuringly, it was also clear that the tests were run in multiple browsers:
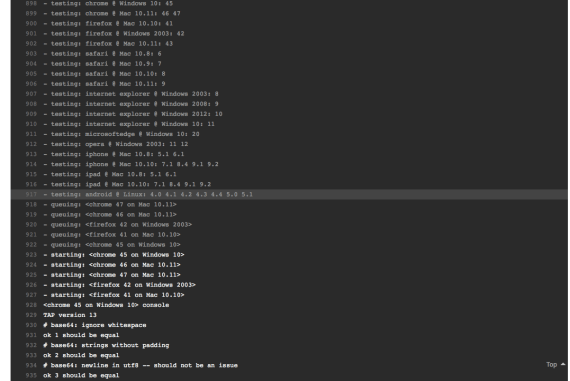
(If your tests are not passing, you can simply keep pushing your commits to that branch, and Travis will re-run the tests for each commit.)
Final step: wait for PR approval or feedback
At this point, I felt confident that my pull request was a good candidate for merging. Even though it made a behavioral change to the code (using strict mode instead of non-strict mode), I predicted it would be uncontroversial, because most JavaScript projects prefer strict mode anyway. Also, strict code will run in non-strict environments, but the reverse is not true. So there is no practical reason to keep the code non-strict.
You might wonder: couldn’t I just remove the 'use strict' now, since we have the fix anyway? Yes, I could, but then it’s always possible that the project will regress in the future, because if anybody changes the code in a way that makes it non-strict, the automated tests won’t catch it. It’s important to guard against future regressions, because as Dale Harvey put it (paraphrasing):
Any untested code will eventually break.
– Harvey’s Law of Software Entropy
This might sound a bit hyperbolic or paranoid, but I’ve seen this truism play out time and time again in my career as an open-source maintainer. If you don’t test something, then eventually someone will commit code (maybe in a seemingly unrelated part of the codebase), and the untested code will start silently failing.
In any case, the maintainer seemed to agree with my choice, because he merged the code and published a new version within a few days. And this fix actually managed to get the “buffer” project down to 0 open PRs and 0 open issues!

Yay, the PR got merged!
Conclusion
I hope that this blog post demonstrates that it’s neither impossible, nor even particularly difficult, to fix a bug in an open-source project. Open-source projects tend to play by different rules than other code (they’re more heavily tested, they discuss bugs out in the open, etc.), but if you’re comfortable committing code to personal or closed-source projects, then there’s no practical reason you couldn’t apply those same skills to the open-source world.
In the case of “buffer,” I found this issue to be sadly emblematic of a lot of open-source bugs. The module itself is heavily relied upon, and the bug is a showstopper, but it remained unresolved for months despite many people running into it. Lots of folks were offering temporary workarounds, but nobody made an attempt to fix the underlying problem.
I suppose the expectation was that the maintainer, Feross Aboukhadijeh, would fix the issue himself. But as you can see from his Github page, he maintains a lot of projects. Personally, I’m a fairly small-time open-source author, but it’s not uncommon for me to get 100 new Github notifications in a day. Feross undoubtedly gets even more than that.
So if you think Feross is going to drop everything to work on one particular bug, you should consider that he probably has dozens of other high-priority tasks on his to-do list. Perhaps he doesn’t even use Webpack or Babel (he seems to prefer Browserify), which means he himself might not get a lot of value out of this bugfix. It’s also arguable that this is actually a bug in Webpack or Babel, since it’s incorrectly trying to run non-strict code in a strict environment.
My takeaway is this: if a bug is impacting you personally, and you’re the one who ran into it, then you are in the best position to fix it. Asking a project maintainer, who has limited time and possibly limited interest in your issue, to both reproduce the bug based on your description and then fix it, is probably the least efficient way to get the issue resolved.
So the next time you run into a bug in an open-source project and are tempted to open a new issue (or to say “+1” or “me too”), please consider trying to fix it instead. Even if you’re only able to reproduce the issue, it’s an enormous help to the project maintainers, who are constantly working to triage new issues and decipher longwinded bug reports.
Open-source software is not manna from heaven. Nor is it a self-renewing resource that magically appears in your codebase, with zero responsibility on your part. Nope: open-source software is the tireless product of human labor and ingenuity, and it needs help from the community to survive.
Projects with an asymmetry of contribution – i.e., many more people benefiting than contributing – will eventually sputter out and even die due to maintainer burnout. You can help prevent this situation, while also giving yourself the sense of personal satisfaction from helping your fellow coders, by simply opening up a pull request.
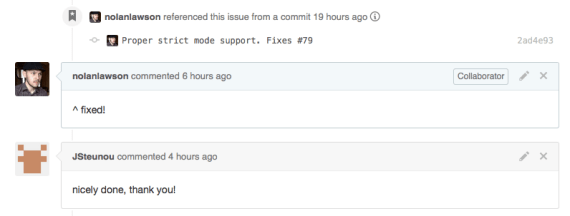
Comments like this make my day.
So if there’s an open-source project you benefit from, consider giving the maintainers the gift of a pull request. Go check out their Github page, open up the list of unresolved issues, and see if anything strikes your fancy. Even if you don’t succeed in fixing a bug, maybe you’ll find ways to improve the documentation, or to make the testing process easier.
There are lots of ways to contribute to open-source software – both big and small. But you won’t know just how easy it can be until you take that first step, and try.
Footnotes
1. For an alternate take on the “Github is your résumé” article, see Why GitHub is not your CV. Although it’s debatable whether your Github profile should influence hiring decisions (or if that only favors folks with the luxury of spare time and energy), I think it’s undeniable that your Github presence does influence your job-hunting prospects. So I still find “beef up your Github profile” to be valuable advice for new programmers. (Anyway, other open-source folks will look at your profile to learn more about you!)
2. Eagle-eyed readers may notice that yes, I am actually a collaborator on the “buffer” project. However, Feross gave me collaborator rights after only two pull requests (because he’s awesome), and I still felt that I was very unfamiliar with the codebase when I tried to tackle this bug. (For instance, I couldn’t remember how to run the tests, or maybe they had changed since I last submitted code.) So I still think this is a good example of fixing a bug in an unfamiliar repo.


Posted by cybervegan on December 29, 2015 at 2:49 AM
“Then I refreshed the browser tests, and suddenly all 84 tests were passing! So apparently, that did the trick.”
That’s not a serious test – you haven’t shown that you understand what the .length property does – how it’s used by other code, what depends on it elsewhere. Tests passing now doesn’t mean you haven’t introduced behaviour changes that will impact on other dependent libraries/code downstream.
This kind of bug fix is the type of thing that causes shell-shock type bugs: not understanding the implications of your changes. The next step shouldn’t be a pull request, bug an investigation of how clients of the library are employing it – do they have expectations on the properties and behaviours of the Buffer object that your change might impact?
I’m not saying you’re wrong, just that beginners need to be shown that no code exists in a vacuum – it interacts with other code, and if you change its behaviour, even in apparently trivial ways, that other code might break.
Posted by Marge on December 29, 2015 at 8:41 AM
Precisely. This post is a nice illustration of specific steps in the process of contributing to a project, but it’s not a good example of a workflow to follow.
Posted by Mario on December 30, 2015 at 7:25 AM
The original bug is fixed and all tests pass. This project is clearly well tested, and I don’t think its wrong to expect at least one of those tests to fail if a breaking change is introduced. Seems to me Nolan did his due dilligence and other concerns (like impacting the expectations on the properties and behaviours of the Buffer object ) should either be covered by tests or brought up by the project maintainer / experienced commiters when reviewing the pull request.
Normally you would expect a committer to include tests for the change in behaviour, but I think for this specific case it might be hard (maybe a separate unit test which forces index.js to load in strict mode? seems kind of trivial when the fix is adding ‘use strict’ at the top of the file)
Suggesting the committer should first know all possible impacts of his change (including expectations of all other users) raises the treshold very high for contributing, especially on projects with a bigger code base. This post is meant to stimulate new committers to try!
Anyway thanks for the article, made me consider the importance of non-code contributions, and contributing to oss in general :)
Posted by Nolan Lawson on December 30, 2015 at 10:15 AM
I got a similar comment on Reddit, so I wrote an extended response over there.
Adding on to that comment: this is a bug essentially in how “buffer” is compiled. I.e. it does not compile correctly on Chrome 43+. Assuming the existing tests already verify the correct behavior, getting it to compile and pass in strict mode is good enough.
And as Mario said, it’s really not the responsibility of every contributor to understand every aspect of the code. Also for the sake of brevity, I omitted some of my hunches about why this fix worked: the Uint8Array object already correctly sets defaults of
length = 0andparent = null, so these assignments are only required for the polyfill, etc.Of course I could have researched this all further, but my point is that a new contributor shouldn’t have to, and a good test setup makes that possible.
Posted by Francis Kim on December 30, 2015 at 5:14 AM
Awesome tips Nolan.
Posted by Nolan Lawson on December 30, 2015 at 10:16 AM
Thanks! :)
Posted by helpful site on March 14, 2016 at 8:20 AM
If you want to get a greaqt deal from this article then you have to apply tjese techniques to your won website.
Posted by 7 Traits That Make Senior Engineers Stand Out From More Junior Team Members - Recruitment Agency in Oxford on August 4, 2016 at 6:53 AM
[…] Developing debugging skills takes time, but it helps if you work on a variety of projects with different people. If you don’t have the opportunity to take on interesting bugs at work, then get involved in an open source project. […]
Posted by Ankit on November 11, 2016 at 6:17 PM
Thanks for the great article! I have one more doubt. I’m a student and I want to contribute to open source projects(and maybe/hopefully participate in google summer of code one day). I found a nice python library that I would like to contribute too, found a few issues labelled as easy/bugs. Now do i start off solving them on my own or should I ask someone to assign the issue to me. I just figured what if someone else is working on this bug (since it was newbie/easy).Wouldn’t it just be redundant for 2 people solving the same issue if one is already midway to the solution )
Posted by Nolan Lawson on November 11, 2016 at 6:20 PM
In my experience it’s very unlikely for two people to take up an issue at the same time. But it’s never a bad idea to take a stab at it and ask for feedback if you get stuck. It’s also good to look at the project history to see if it’s a very active project, less active project, or “maintenance mode” project to gauge what kind of reaction you’ll get. It’s more of an art than a science and takes a bit of practice. :)
Posted by Ankit on November 11, 2016 at 6:50 PM
Thanks a lot:)