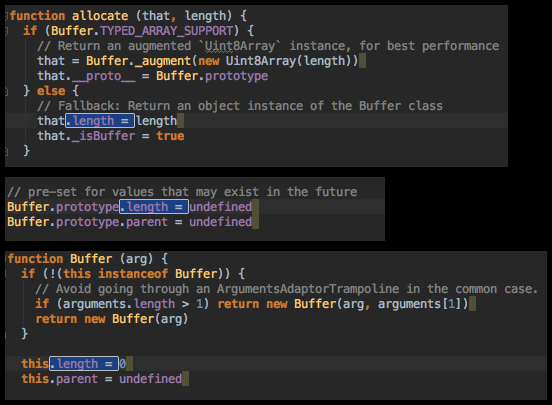
Outside your door stands a line of a few hundred people. They are patiently waiting for you to answer their questions, complaints, pull requests, and feature requests.
You want to help all of them, but for now you’re putting it off. Maybe you had a hard day at work, or you’re tired, or you’re just trying to enjoy a weekend with your family and friends.
But if you go to github.com/notifications, there’s a constant reminder of how many people are waiting:

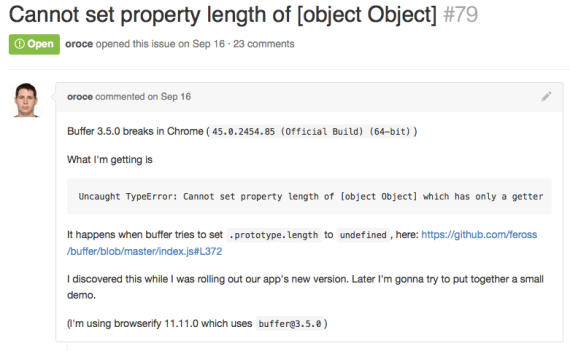
When you manage to find some spare time, you open the door to the first person. They’re well-meaning enough; they tried to use your project but ran into some confusion over the API. They’ve pasted their code into a GitHub comment, but they forgot or didn’t know how to format it, so their code is a big unreadable mess.
Helpfully, you edit their comment to add a code block, so that it’s nicely formatted. But it’s still a lot of code to read.
Also, their description of the problem is a bit hard to understand. Maybe this person doesn’t speak English as a first language, or maybe they have a disability that makes it difficult for them to communicate via writing. You’re not sure. Either way, you struggle to understand the paragraphs of text they’ve posted.
Wearily, you glance at the hundreds of other folks waiting in line behind them. You could spend a half-hour trying to understand this person’s code, or you could just skim through it and offer some links to tutorials and documentation, on the off-chance that it will help solve their problem. You also cheerfully suggest that they try Stack Overflow or the Slack channel instead.
The next person in line has a frown on their face. They spew out complaints about how your project wasted 2 hours of their life because a certain API didn’t work as advertised. Their vitriol gives you a bad feeling in the pit of your stomach.
You don’t waste a lot of time on this person. You simply say, “This is an open-source project, and it’s maintained by volunteers. If there’s a bug in the code, please submit a reproducible test case or a PR.”
The next person has run into a very common error, with an easy workaround. You know you’ve seen this error a few times before, but can’t quite recall where the solution was posted. Stack Overflow? The wiki? The mailing list? After a few minutes of Googling, you paste a link and close the issue.
The next person is a regular contributor. You recognize their name from various community forums and sibling projects. They’ve run into a very esoteric issue and have proposed a pull request to fix it. Unfortunately the issue is complicated, and so their PR contains many paragraphs of prose explaining it.
Again, your eye darts to the hundreds of people still waiting in line. You know that this person put a lot of work into their solution, and it’s probably a reasonable one. The Travis tests passed, and so you’re tempted to just say "LGTM" and merge the pull request.
However, you’ve been burned by that before. In the past, you’ve merged a PR without fully evaluating it, and in the end it led to new headaches because of problems you failed to foresee. Maybe the tests passed, but the performance degraded by a factor of ten. Or maybe it introduced a memory leak. Or maybe the PR made the project too confusing for new users, because it excessively complicated the API surface.
If you merge this PR now, you might wind up with even more issues tomorrow, because you broke someone else’s workflow by solving this one person’s (very edge-casey) problem. So you put it on the back burner. You’ll get to it later when you have more time.
The next person in line has found a new bug, but you know that it’s actually a bug in a sibling project. They’re saying that this is blocking them from shipping their app. You know it’s a big problem, but it’s one of many, and so you don’t have time to fix it right now.
You respond that this looks like a genuine issue, but it’s more appropriate to open in another repo. So you close their issue and copy it into the other repo, then add a comment suggesting where they might look in the code to start fixing it. You doubt they’ll actually do so, though. Very few do.
The next person just says “What’s the status on this?” You’re not sure what they’re talking about, so you look at the context. They’ve commented on a lengthy GitHub thread about a long-standing bug in the project. Many people disagreed on the proper solution to the problem, so it generated a lot of discussion.
There are more than 20 comments on this particular issue, and it would take you a long time to read through them all to jog your memory. So you merely respond, “Sorry, this issue has been open for a while, but nobody has tackled it yet. We’re still trying to understand the scope of the problem; a pull request could be a good start!”
The next person is just a GreenKeeper bot. These are easy. Except that this particular repo has fairly flaky tests, and the tests failed for what looks like a spurious reason, so you have to restart them to pass. You restart the tests and try to remind yourself to look into it later after Travis has had a chance to run.
The next person has opened a pull request, but it’s on a repo that’s fairly active, and so another maintainer is already providing feedback. You glance through the thread; you trust the other maintainer to handle this one. So you mark it as read and move on.
The next person has run into what appears to be a bug, and it’s not one you’ve ever seen before. But unfortunately they’ve provided scant details on how the problem actually occurred. What browser was it? What version of Node? What version of the project? What code did they use to reproduce it? You ask them for clarification and close the tab.
The constant stream
After a while, you’ve gone through ten or twenty people like this. There are still more than a hundred waiting in line. But by now you’re feeling exhausted; each person has either had a complaint, a question, or a request for enhancement.
In a sense, these GitHub notifications are a constant stream of negativity about your projects. Nobody opens an issue or a pull request when they’re satisfied with your work. They only do so when they’ve found something lacking. Even if you only spend a little bit of time reading through these notifications, it can be mentally and emotionally exhausting.
Your partner has observed that you’re always grumpy after going through this ritual. Maybe you found yourself snapping at her for no reason, just because you were put in a sour mood. “If doing open source makes you so angry, why do you even do it?” she asks. You don’t have a good answer.
You could take a break; in fact you’ve probably earned it by now. In the past, you’ve even taken vacations of a week or two from GitHub, just for your own mental health. But you know that that’s exactly how you ended up in this situation, with hundreds of people patiently waiting.
If you had just kept on top of your GitHub notifications, you’d probably have a more manageable 20-30 to deal with per day. Instead you let them pile up, so now there are hundreds. You feel guilty.
In the past, for one reason or another, you’ve really let issues pile up. You might have seen an issue that was left unanswered for months. Usually, when you go back to address such an issue, the person who opened it never responds. Or they respond by saying, “I fixed my problem by abandoning your project and using another one instead.” That makes you feel bad, but you understand their frustration.
You’ve learned from experience that the most pragmatic response to these stale issues is often just to say, “I’m closing old issues. Please reopen if this is still a problem for you or if you can provide more details.” Usually there is no response. Sometimes there is, but it’s just an angry comment about how they were made to wait for so long.
So nowadays you try to be more diligent about staying on top of your notifications. Hundreds of people waiting in line are far too many. You long for that line to get down to a hundred, or a dozen, or even the mythical inbox zero. So you press on.
Attracting new contributors
After triaging enough issues like this, even if you eventually reach inbox zero, you might still end up with a large backlog of open bugs and pull requests. Labeling can help – for instance, you might label issues as “needs reproducing” or “has test case” or “good first patch.” The “good first patch” ones can be especially helpful, since they often attract new contributors.
However, you’ve noticed that often the only issues that attract new contributors are the very easy ones, the ones where the effort to document the issue and explain how to fix it outweighs the effort to just fix it yourself. You create some of these issues, because you know it’s a worthy goal to get new people involved in open source, and you feel good when the pull request author tells you, “This was my first contribution to an open-source project.”
But you know it’s very unlikely that they’ll ever come back; usually these folks don’t become regular contributors or maintainers. You wonder if you did something wrong, if there’s something more you could have done to onboard new maintainers and help lighten your load.
One of your projects is nearly self-sustaining. You haven’t touched it in years, but there’s a group of maintainers who respond to every issue and PR, so you don’t have to. You’re enormously grateful to these maintainers. But you have no idea what you did to get so many contributors to this project, whereas other projects wind up as your responsibility and yours alone.
Looking ahead
You’re reluctant to create new projects, because you know it will just increase your maintenance burden. In fact, there’s a perverse effect where, the more successful you are, the more you get “punished” with GitHub notifications.
You can still recall the thrill of creation, the joy of writing a new project from scratch and solving a previously-unsolved problem. But now you weigh that joy against the knowledge that any new project will necessarily steal time from old projects. You wonder if it it’s time to formally deprecate one of your old repos, or to mark it as unmaintained.
You wonder how much longer this can go on before you just burn out. You’ve considered doing open source as your day job, but from talking with folks who actually do open source for a living, you know that this usually means permission to work on a specific open-source project as your day job. That doesn’t help you much, because you have dozens of projects across various domains, which are all vying for your time.
What you want most of all is to have more projects that maintain themselves. You try to follow all the best practices: you have a CONTRIBUTING.md and a code of conduct, you enthusiastically hand out owner privileges to anyone who submits a high-quality PR. It’s exhausting to do this for every project, though, so you’re not as diligent as you wish you could be.
You feel guilty about that too, since you know open source is frequently regarded as an exclusive club for privileged white males, like yourself. So you worry that you’re not doing enough to help fix that problem.
More than anything, you feel the guilt: the guilt of knowing that you could have helped someone solve their problem, but instead you let their issue rot for months before closing it. Or the guilt of knowing that someone opened their first pull request ever on your repo, but you didn’t have time to respond to it, and because of that, you may have permanently discouraged them from open source. You feel guilty for the work that you do, for the work that you didn’t do, and for not recruiting more people to share in your unhappy guilt-ridden experience.
Putting it all together
Everything I’ve said above is based on my own experiences. I can’t claim to speak for all people who do open-source software, but this is what it feels like to me.
I’ve been doing open source for a long time (roughly seven years), and I’ve been reluctant to complain about any of this, because I worried it could be perceived as melodramatic whining from someone who ought to know better. After all, isn’t this situation one of my own making? I could walk away from GitHub whenever I want; I have no obligations to anyone.
Also, shouldn’t I be grateful? My work on open source has helped give me my standing in the community. I get invitations to speak at conferences. I have thousands of Twitter followers who listen to what I have to say and hold my opinion in high esteem. Arguably, I got my job at Microsoft because of my experience in open source. Who am I to complain?
And yet, I’ve known many others in positions similar to mine who have burned out. Folks who enthusiastically merged pull requests, fixed issues, and wrote blog posts about their projects, before vanishing without a trace. For some of these people, I don’t even bother opening issues on their repos, because I know they won’t respond. I don’t hold it against them, but I worry that I’ll share their fate.
I’ve already taken plenty of self-care measures. I don’t use the GitHub notification interface anymore – I use email filters, so that I can categorize my notifications based on project (unmaintained ones get ignored) or type of notification (at-mentions and threads I’ve commented on usually deserve higher priority). Since it’s email, this also helps me work offline and manage everything in one place.
Often I will get emails out of the blue asking for support on a project that I’ve long stopped maintaining (I still get at least one per month about this one, for instance), and usually I just don’t even respond to those. I also tend to ignore comments on my blog posts, responses to Stack Overflow answers, and mailing list questions. I aggressively un-watch repos that I feel someone else is doing a good enough job of maintaining.
One reason this situation is so frustrating is that, increasingly, I find that issue triage takes time away from the actual maintenance of a project. In other words, I often only have enough time to read through an issue and say, “Sorry, I don’t have time to look at this right now.” Just the mere act of responding can take up a majority of the time I’ve set aside for open source.
Issue templates, GreenKeeper, Travis, travis_retry, Coveralls, Sauce Labs… there are so many technical solutions to the problems of open-source maintenance, and I’m grateful to all of them. There’s no way I’d be able to keep my head on straight if I didn’t have these automated tools. But at some point you run up against issues that are more social problems than technical problems. One human being just doesn’t scale. I’m not even in the top 100 npm maintainers and I’m already feeling the squeeze; I can’t imagine how those hundred people must feel.
I’ve already told my partner that, if and when we decide to start having kids, I will probably quit open source for good. I just can’t see how I’ll be able to make the time for both raising a family and doing open source. I anticipate that ultimately this will be the solution to my problem: the nuclear option. I just hope it comes in a positive form, like starting a new chapter of my life, and not in a negative form, like unceremoniously burning out.
Closing thoughts
If you’ve read this far and are interested in the problems plaguing open-source communities and potential solutions, you may want to look into “Roads and Bridges” by Nadia Eghbal. It’s probably the clearest-eyed and most thorough analysis of the problem.
I’m also open to suggestions, although keep in mind that I’m very reluctant to mix money and labor in my open-source projects (for perhaps silly idealistic reasons). But I have seen it work well for other projects.
Note that despite all the negativity expressed above, I still feel that open source has been a valuable addition to my life, and I don’t regret any of it. But I hope this is a useful window into how it can feel to be a victim of your own success, and to feel weighed down by all the work left undone.
If there’s one thing I’ve learned in open source, it’s this: the more work you do, the more work gets asked of you. There is no solution to that problem that I’m aware of.
Please feel free to comment on Twitter and to read responses by Mikeal Rogers and Jan Lehnardt.