The error reports page in the Android Market Developer Console is one of my favorite additions to Android 2.2 (Froyo):

It gives you a nice, organized view of the stacktraces reported by users when your app has crashed or frozen. This is great because, for the most part, users are not particularly eloquent when describing bugs. Usually they just say something like “Doesn’t work anymore, please fix.” And when they do give more information, it’s often tantalizingly incomplete: “When I go to Settings I get a force close.”
Stacktraces, on the other hand, don’t beat around the bush:
java.lang.RuntimeException: Failure delivering result ResultInfo{who=null, request=0, result=-1, data=Intent { (has extras) }} to activity {com.nolanlawson.pokedex/com.nolanlawson.pokedex.PokedexActivity}: java.lang.NullPointerException
at android.app.ActivityThread.deliverResults(ActivityThread.java:3515)
at android.app.ActivityThread.handleSendResult(ActivityThread.java:3557)
at android.app.ActivityThread.access$2800(ActivityThread.java:125)
at android.app.ActivityThread$H.handleMessage(ActivityThread.java:2063)
at android.os.Handler.dispatchMessage(Handler.java:99)
at android.os.Looper.loop(Looper.java:123)
at android.app.ActivityThread.main(ActivityThread.java:4627)
at java.lang.reflect.Method.invokeNative(Native Method)
at java.lang.reflect.Method.invoke(Method.java:521)
at com.android.internal.os.ZygoteInit$MethodAndArgsCaller.run(ZygoteInit.java:868)
at com.android.internal.os.ZygoteInit.main(ZygoteInit.java:626)
at dalvik.system.NativeStart.main(Native Method)
Caused by: java.lang.NullPointerException
at com.nolanlawson.pokedex.VoiceSearcher.guessMonsterUsingDirectLookup(VoiceSearcher.java:132)
at com.nolanlawson.pokedex.PokedexActivity.receiveVoiceResults(PokedexActivity.java:1206)
at com.nolanlawson.pokedex.PokedexActivity.onActivityResult(PokedexActivity.java:1178)
at android.app.Activity.dispatchActivityResult(Activity.java:3890)
at android.app.ActivityThread.deliverResults(ActivityThread.java:3511)
... 11 more
NullPointerException. Bam. Go to the line in the code, figure out what’s null, and fix it. Nothing clarifies a bug like a good old-fashioned stacktrace.
Before Android 2.2, you had to get this kind of information from users by having them download a Logcat app and go through all the tedious effort of recording the log, reproducing the bug, and sending the stacktrace to you. Users can hardly be blamed for a lack of enthusiasm about this process. When you’re trying to complete a task and an app force-closes on you, the last thing you think is “Oh goody! I should tell the developer about this!”

Oh goody!
So Froyo’s error reporting framework is a godsend. From the user’s point of view, it’s a lot less painful to just click the “Report” button than to go through the rigamarole of downloading a Logcat app and emailing the developer. (Although, there is a splendid little Logcat app out there.) And from the developer’s point of view, your users have become an army of testers – and good ones, at that! They give you stacktraces and everything!
Plus, even when the stacktrace is not enough information, the additional comments from users are sometimes enough to squash the bug. For instance, I recently had an ArrayIndexOutOfBoundsException that was reported by almost a hundred Pokédroid users after the release of version 1.4.4. Try as I might, though, I couldn’t reproduce it. Then I noticed the user comments:
- 셋팅 클릭시 프로그램 종료됨
- Every time I open settings it shuts it self down. Galaxy ACE
- se cierra al entrar en “Settings”
- 렉 너무걸린다
- När man ska gå in på inställningar så hänger programet sig
- Happens every time I go to the settings
- whenever I go to settings, the program crashes
- I has updated this app and now when i want to change settings that not working! I mean i cant change settings! :-( sorry about my bad english :-(
- It crashes while I try to enter the settings
- trying to open settings. always happens. samsung galaxy s. android 2.2
- when click on settings freeze
- Telkens als ik naar settings wil gaan dan flipt ie
- i was trying to go to the settings-screen… crashes whenever i try it…
- Opened settings
Hmm… there sure are a lot of non-English comments here. So I set my phone to French and, aha! It turned out the bug only occurred if your phone’s language was set to something other than English. The bug was fixed and I shipped out 1.4.5 that same day. (Another great thing about the Android Market – no review process!)
When you have an app with a lot of downloads, though (like Pokédroid, which just hit 250,000), you start seeing some strange little bugs:
java.lang.NullPointerException
at com.lge.media.SprintMultimedia.isStreaming(SprintMultimedia.java:27)
at android.media.MediaPlayer.setDataSource(MediaPlayer.java:738)
Caused by: android.database.sqlite.SQLiteDatabaseCorruptException: database disk image is malformed
at android.database.sqlite.SQLiteQuery.native_fill_window(Native Method)
java.lang.NullPointerException
at com.motorola.android.widget.TextViewHelper.drawCursorHalo(TextViewHelper.java:306)
at android.widget.TextView.onDraw(TextView.java:4175)
at android.view.View.draw(View.java:6742)
Caused by: java.io.FileNotFoundException: res/drawable-hdpi/ic_dialog_alert.png
at android.content.res.AssetManager.openNonAssetNative(Native Method)
Most of these just aren’t worth the effort to fix. For instance, they might only be reported by one or two users, and reflect situations that you, as a developer, don’t have a lot of control over (“database disk image is malformed”?). Others may be bugs in proprietary builds of Android, like the Motorola and Sprint bugs above. Obviously, I’m not going to go out and buy every flavor of Android phone just to test a few stray bugs.
If you’re lucky, you may also run into the Bigfoot of Android bugs:
java.lang.RuntimeException: Unable to get provider com.nolanlawson.pokedex.PokedexContentProvider: java.lang.ClassNotFoundException: com.nolanlawson.pokedex.PokedexContentProvider in loader dalvik.system.PathClassLoader[/mnt/asec/com.nolanlawson.pokedex-1/pkg.apk]
at android.app.ActivityThread.installProvider(ActivityThread.java:4969)
at android.app.ActivityThread.installContentProviders(ActivityThread.java:4696)
at android.app.ActivityThread.handleBindApplication(ActivityThread.java:4652)
at android.app.ActivityThread.access$3000(ActivityThread.java:140)
at android.app.ActivityThread$H.handleMessage(ActivityThread.java:2225)
at android.os.Handler.dispatchMessage(Handler.java:99)
at android.os.Looper.loop(Looper.java:143)
at android.app.ActivityThread.main(ActivityThread.java:5097)
at java.lang.reflect.Method.invokeNative(Native Method)
at java.lang.reflect.Method.invoke(Method.java:521)
at com.android.internal.os.ZygoteInit$MethodAndArgsCaller.run(ZygoteInit.java:868)
at com.android.internal.os.ZygoteInit.main(ZygoteInit.java:626)
at dalvik.system.NativeStart.main(Native Method)
Caused by: java.lang.ClassNotFoundException: com.nolanlawson.pokedex.PokedexContentProvider in loader dalvik.system.PathClassLoader[/mnt/asec/com.nolanlawson.pokedex-1/pkg.apk]
at dalvik.system.PathClassLoader.findClass(PathClassLoader.java:243)
at java.lang.ClassLoader.loadClass(ClassLoader.java:573)
at java.lang.ClassLoader.loadClass(ClassLoader.java:532)
at android.app.ActivityThread.installProvider(ActivityThread.java:4954)
... 12 more

I want to believe.
I call this the Bigfoot Bug because, if you Google it, you will find a lot of puzzled developers saying that they’ve only ever seen this bug reported in the Android Market, and they can’t reproduce it themselves. I mean, “ClassNotFoundException”? The class is right there! I was stumped by this bug myself, until I saw one developer suggest:
AFAICT, the installation process sometimes leaves the app in a corrupt state leading to weird errors like this.
So apparently, this bug is just one of those unavoidable parts of life, like sitting through red lights or having the sushi fall apart when you dip it in the soy sauce. You just have to put up with it.
Still, if you can manage to not get overwhelmed by the sheer number of reported bugs (Pokédroid has gotten over 500), and if you can prioritize them based on how many users they affect, the Froyo error reports can be an invaluable tool in making your app more stable. For instance, I had a layout-related bug a few months ago that I could not reproduce. It was reported by enough users, though, that I finally decided to rewrite that bit of the code and do some long-overdue optimizations. I haven’t seen the bug since.
















 (by Bayes’ Law)
(by Bayes’ Law)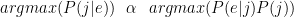
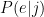 part. So I modeled that as:
part. So I modeled that as: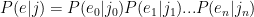
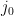 through
through 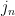 (i.e. the Japanese substring partitionings, e.g n|oo|r|a|n), my task boiled down to just generating every possible partitioning, calculating the probability for each one, and then taking the max.
(i.e. the Japanese substring partitionings, e.g n|oo|r|a|n), my task boiled down to just generating every possible partitioning, calculating the probability for each one, and then taking the max.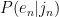 , i.e. the probability of an English letter given a Japanese substring? Co-occurrence counts seemed like the most intuitive choice here – just answering the question “how likely am I to see this English character, given the Japanese substring I’m aligning it with?” Then I could just take the product of all of those probabilities. So, for instance, in the case of “nolan” -> “nooran”, the ideal partitioning would be n|oo|r|a|n, and to figure that out I would calculate count(n,n)/count(n) * count(o,oo)/count(o) * count(l,r)/count(l) * count(a,a)/count(a) * count(n,n)/count(n), which should be the highest-scoring partitioning for that pair.
, i.e. the probability of an English letter given a Japanese substring? Co-occurrence counts seemed like the most intuitive choice here – just answering the question “how likely am I to see this English character, given the Japanese substring I’m aligning it with?” Then I could just take the product of all of those probabilities. So, for instance, in the case of “nolan” -> “nooran”, the ideal partitioning would be n|oo|r|a|n, and to figure that out I would calculate count(n,n)/count(n) * count(o,oo)/count(o) * count(l,r)/count(l) * count(a,a)/count(a) * count(n,n)/count(n), which should be the highest-scoring partitioning for that pair.
