Update: CouchDroid has been renamed to PouchDroid, and I’ve released version 0.1.0. The code examples below are out of date. Please refer to the instructions and tutorials on the GitHub page.
I love PouchDB. It demonstrates the strength and flexibility of CouchDB, and since it supports both WebSQL and IndexedDB under the hood, it obviates the need to learn their separate APIs (or to worry about the inevitable browser inconsistencies). If you know CouchDB, you already know PouchDB.
And most importantly, it offers two-way sync in just a few lines of code. To me, this is magical:
var db = new PouchDB('mydb')
db.replicate.to('http://foo.com:5984/db', {continuous : true});
db.replicate.from('http://foo.com:5984/db', {continuous : true});
I wanted to bring this same magic to Android, so I started working on an Android adapter for PouchDB. I’m calling it CouchDroid, until I can think of a better name. The concept is either completely crazy or kinda clever, which is why I’m writing this post, in the hopes of getting early feedback.
The basic idea is this: instead of rewriting PouchDB in Java, I fire up an invisible WebView that runs PouchDB in JavaScript. I override window.openDatabase to redirect to the native Java SQLite APIs, so that all of the SQL queries run on a background thread (instead of tying up the UI thread, like they normally would). I also redirect XMLHttpRequest into Java, giving me control over the HTTP request threads, and helping avoid any messy server-side configuration of CORS/JSONP for web security.
Result: it works on a fresh CouchDB installation, no assembly required. And it’s actually pretty damned fast.
The code is still a little rough around the edges, but it can already do bidirectional sync, which is great. Callbacks look weird in Java, but static typing, generics, and content assist make the Pouch APIs a dream to work with. (My precious Ctrl+space works!)
Here’s an example of bidirectional sync between two Android devices and a CouchDB server using CouchDroid. First, we define what kinds of documents we want to sync by extending PouchDocument. This is Android, so let’s store some robots:
public class Robot extends PouchDocument {
private String name;
private String type;
private String creator;
private double awesomenessFactor;
private int iq;
private List<RobotFunction> functions;
// constructors, getters, setters, toString...
}
public class RobotFunction {
private String name;
// constructors, getters, setters, toString...
}
I’m using Jackson for JSON serialization/deserialization, which means that your standard POJOs “just work.” The PouchDocument abstract class simply adds the required CouchDB fields _id and _rev.
In our Activity, we extend CouchDroidActivity (needed to set up the Java <-> JavaScript bridge), and we add a bunch of robots to a PouchDB<Robot>:
public class MainActivity extends CouchDroidActivity {
private PouchDB<Robot> pouch;
// onCreate()...
@Override
protected void onCouchDroidReady(CouchDroidRuntime runtime) {
pouch = PouchDB.newPouchDB(Robot.class, runtime, "robots.db");
List<Robot> robots = Arrays.asList(
new Robot("C3P0", "Protocol droid", "George Lucas", 0.4, 200,
Arrays.asList(
new RobotFunction("Human-cyborg relations"),
new RobotFunction("Losing his limbs"))),
new Robot("R2-D2", "Astromech droid", "George Lucas", 0.8, 135,
Arrays.asList(
new RobotFunction("Getting lost"),
new RobotFunction("Having a secret jetpack"),
new RobotFunction("Showing holographic messages")))
);
pouch.bulkDocs(robots, new BulkCallback() {
@Override
public void onCallback(PouchError err, List<PouchInfo> info) {
Log.i("Pouch", "loaded: " + info);
}
});
}
}
Meanwhile, on another Android device, we load a completely different list of robots:
List<Robot> robots = Arrays.asList(
new Robot("Mecha Godzilla", "Giant monster", "Toho", 0.4, 82,
Arrays.asList(
new RobotFunction("Flying through space"),
new RobotFunction("Kicking Godzilla's ass"))),
new Robot("Andy", "Messenger robot", "Stephen King", 0.8, 135,
Arrays.asList(
new RobotFunction("Relaying messages"),
new RobotFunction("Betraying the ka-tet"),
new RobotFunction("Many other functions"))),
new Robot("Bender", "Bending Unit", "Matt Groening", 0.999, 120,
Arrays.asList(
new RobotFunction("Gettin' drunk"),
new RobotFunction("Burping fire"),
new RobotFunction("Bending things"),
new RobotFunction("Inviting you to bite his lustrous posterior")))
);
And, of course, we set up bidirectional replication on both pouches:
String remoteCouch = "http://user:password@myhost:5984/robots";
Map<String, Object> options = Maps.quickMap("continuous", true);
pouch.replicateFrom(remoteCouch, options);
pouch.replicateTo(remoteCouch, options);
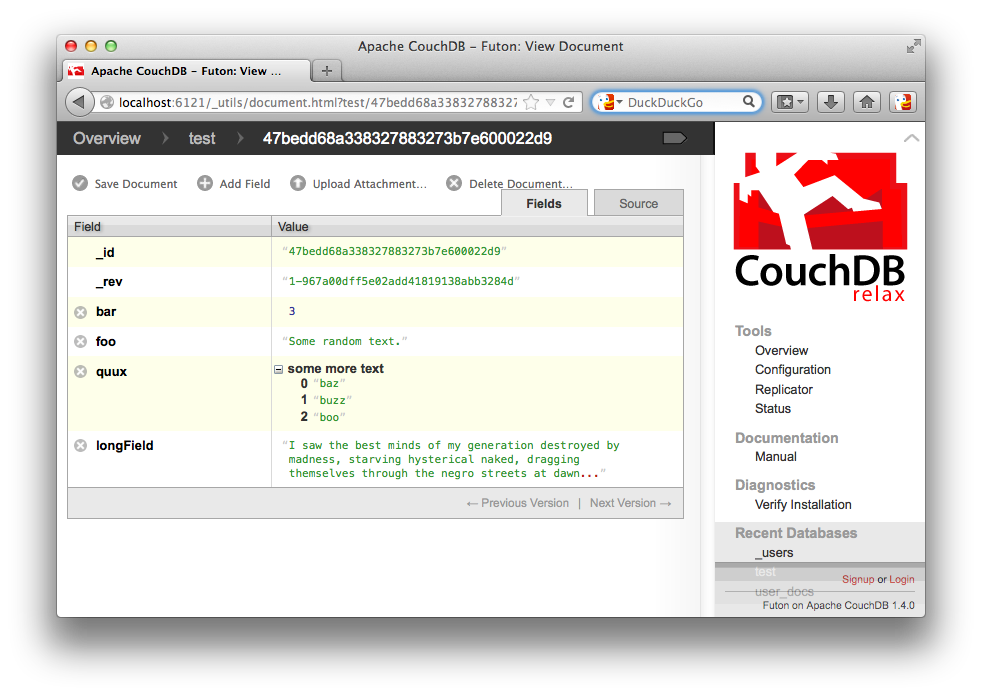
Wait a few seconds (or pass in a callback), and voilà! You can check the contents on CouchDB:
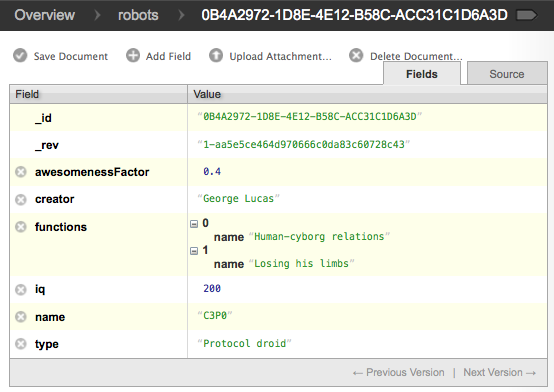
And then check the contents of each PouchDB on Android:
pouch.allDocs(true, new AllDocsCallback<Robot>() {
@Override
public void onCallback(PouchError err, AllDocsInfo<Robot> info) {
List<Robot> robots = info.getDocuments();
Log.i("Pouch", "pouch contains " + robots);
}
});
This prints:
pouch contains [Robot [name=Bender, type=Bending Unit, creator=Matt Groening,
awesomenessFactor=0.999, iq=120, functions=[RobotFunction [name=Gettin' drunk], RobotFunction
[name=Burping fire], RobotFunction [name=Bending things], RobotFunction [name=Inviting you to bite
his lustrous posterior]]], Robot [name=C3P0, type=Protocol droid, creator=George Lucas,
awesomenessFactor=0.4, iq=200, functions=[RobotFunction [name=Human-cyborg relations], RobotFunction
[name=Losing his limbs]]], Robot [name=Mecha Godzilla, type=Giant monster, creator=Toho,
awesomenessFactor=0.4, iq=82, functions=[RobotFunction [name=Flying through space], RobotFunction
[name=Kicking Godzilla's ass]]], Robot [name=R2-D2, type=Astromech droid, creator=George Lucas,
awesomenessFactor=0.8, iq=135, functions=[RobotFunction [name=Getting lost], RobotFunction
[name=Having a secret jetpack], RobotFunction [name=Showing holographic messages]]], Robot
[name=Andy, type=Messenger robot, creator=Stephen King, awesomenessFactor=0.8, iq=135, functions=
[RobotFunction [name=Relaying messages], RobotFunction [name=Betraying the ka-tet], RobotFunction
[name=Many other functions]]]]
So within seconds, all five documents have been synced to two separate PouchDBs and one CouchDB. Not bad!
In addition to adapting the PouchDB API for Java, I also wrote a simple migration tool to mirror an existing SQLite database to a remote CouchDB. It could be useful, if you just want a read-only web site where users can view their Android data:
new CouchDroidMigrationTask.Builder(runtime, sqliteDatabase)
.setUserId("fooUser")
.setCouchdbUrl("http://user:password@foo.com:5984/db")
.addSqliteTable("SomeTable", "uniqueId")
.addSqliteTable("SomeOtherTable", "uniqueId")
.setProgressListener(MainActivity.this)
.build()
.start();
This converts SQLite data like this:
sqlite> .schema Monsters
CREATE TABLE Monsters (_id integer primary key autoincrement,
uniqueId text not null,
nationalDexNumber integer not null,
type1 text not null,
type2 text,
name text not null);
sqlite> select * from Monsters limit 1
1|001|1|Grass|Poison|Bulbasaur
into CouchDB data like this:
{
"_id": "fooUser~pokemon_11d1eaac.db~Monsters~001",
"_rev": "1-bd52d48dba37ce490c38d455726296f0",
"table": "Monsters",
"user": "fooUser",
"sqliteDB": "pokemon_11d1eaac.db",
"appPackage": "com.nolanlawson.couchdroid.example1",
"content": {
"_id": 1,
"uniqueId": "001",
"nationalDexNumber": 1,
"type1": "Grass",
"type2": "Poison",
"name": "Bulbasaur"
}
}
Notice that the user is included as a field and as part of the _id, so you can easily set up per-user write privileges. For per-user read privileges, you still need to set up one database per user.
CouchDroid isn’t ready for a production release yet. But even in its rudimentary state, I think it’s pretty damn exciting. As Android developers, wouldn’t it be great if we didn’t have to write so many SQL queries, and we could just put and get our POJOs? And wouldn’t it be awesome if that data were periodically synced to the server, so we didn’t even have to think about intermittent availability or incremental sync or conflict resolution or any of that junk? And wouldn’t our lives be so much easier if the data was immediately available in a RESTful web service like CouchDB, so we didn’t even need to write any server code? The dream is big, but it’s worth pursuing.
For more details on the project, check it out on GitHub. The sample apps in the examples directory are a good place to start. Example #1 is the migration script above, Example #2 is some basic CRUD operations on the Pouch API, and Example #3 is the full bidirectional sync described above. More to come!

























{kind=link}