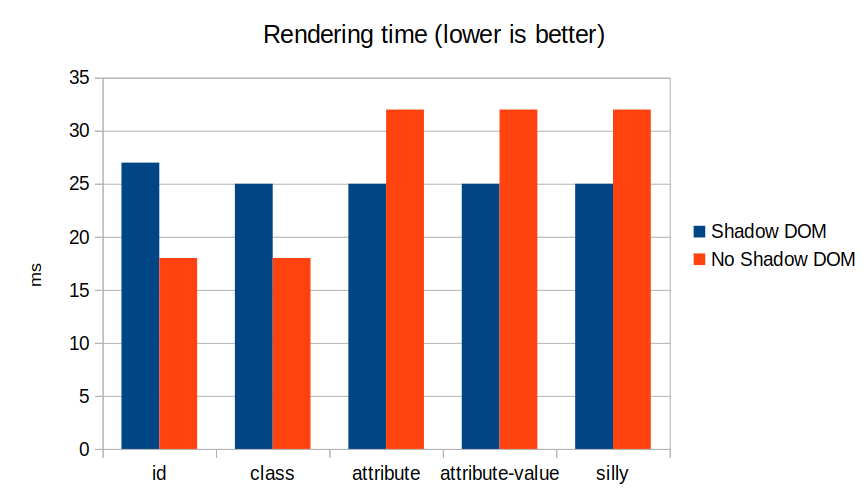
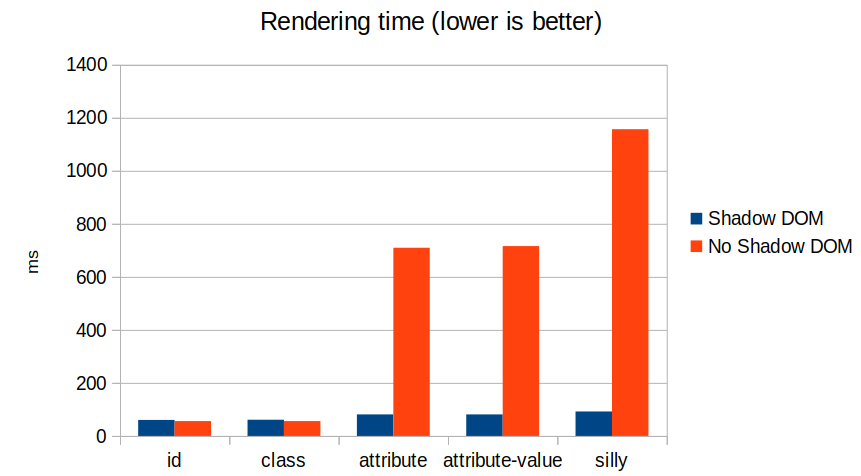
Web components are kind of having a moment right now. And as part of that, shadow DOM is having a bit of a moment too. Or it would, except that much of the conversation seems to be about why you shouldn’t use shadow DOM.
For example, “HTML web components” are based on the idea that you should use most of the goodness of web components (custom elements, lifecycle hooks, etc.), while dropping shadow DOM like a bad habit. (Another name for this is “light DOM components.”)
This is a perfectly fine pattern for certain cases. But I also think some folks are confused about the tradeoffs with shadow DOM, because they don’t understand what shadow DOM is supposed to accomplish in the first place. In this post, I’d like to clear up some of the misconceptions by explaining what shadow DOM is supposed to do, while also weighing its success in actually achieving it.
What the heck is shadow DOM for
The main goal of shadow DOM is encapsulation. Encapsulation is a tricky concept to explain, because the benefits are not immediately obvious.
Let’s say you have a third-party component that you’ve decided to include on your website or webapp. Maybe you found it on npm, and it solved some use case very nicely. Let’s say it’s something simple, like a dropdown component.

You know what, though? You really don’t like that caret character – you’d rather have a 👇 emoji. And you’d really prefer rounded corners. And the theme color should be red instead of blue. So you hack together some CSS:
.dropdown {
background: red;
border-radius: 8px;
}
.dropdown .caret::before {
content: '👇';
}

Great! You get the styling you want. Ship it.
Except that 6 months later, the component has an update. And it’s to fix a security vulnerability! Your boss is pressuring you to update the component as fast as possible, since otherwise the website won’t pass a security audit anymore. So you go to update, and…
Everything’s broken.
It turns out that the component changed their internal class name from dropdown to picklist. And they don’t use CSS content for the caret anymore. And they added a wrapper <div>, so the border-radius needs to be applied to something else now. Suddenly you’re in for a world of hurt, just to get the component back to the way it used to look.
Global control is great until it isn’t
CSS gives you an amazing superpower, which is that you can target any element on the page as long as you can think of the right selector. It’s incredibly easy to do this in DevTools today – a lot of people are trained to right-click, “Inspect Element,” and rummage around for any class or attribute to start targeting the element. And this works great in the short term, but it affects the long-term maintainability of the code, especially for components you don’t own.
This isn’t just a problem with CSS – JavaScript has this same flaw due to the DOM. Using document.querySelector (or equivalent APIs), you can traverse anywhere you want in the DOM, find an element, and apply some custom behavior to it – e.g. adding an event listener or changing its internal structure. I could tell the same story above using JavaScript rather than CSS.
This openness can cause headaches for component authors as well as component consumers. In a system where the onus is on the component author to ship new versions (e.g. a monorepo, a platform, or even just a large codebase), component authors can effectively get frozen in time, unable to ship any internal refactors for fear of breaking their downstream consumers.
Shadow DOM attempts to solve these problems by providing encapsulation. If the third-party dropdown component were using shadow DOM, then you wouldn’t be able to target arbitrary content inside of it (except with elaborate workarounds that I don’t want to get into).
Of course, by closing off access to global styling and DOM traversal, shadow DOM also greatly limits a component’s customizability. Consumers can’t just decide they want a background to be red, or a border to be rounded – the component author has to provide an explicit styling API, using tools like CSS custom properties or parts. E.g.:
snazzy-dropdown {
--dropdown-bg: red;
}
snazzy-dropdown::part(caret)::before {
content: '👇';
}
By exposing an explicit styling API, the risk of breakage across component upgrades is heavily reduced. The component author is effectively declaring an API surface that they intend to support, which limits what they need to keep stable over time. (This API can still break, as with a major version bump, but that’s another story.)
Tradeoffs
When people complain about shadow DOM, they seem to mostly be complaining about style encapsulation. They want to reach in and add a rounded corner on some component, and roll the dice that the component doesn’t change in the future. Depending on what kind of website you’re building, this can be a perfectly acceptable tradeoff. For example:
- A portfolio site
- A news article with interactive charts
- A marketing site for a Super Bowl campaign
- A landing page that will be rewritten in 2 years anyway
In all of these cases, long-term maintenance is not really a big concern. The page either has a limited shelf life, or it’s just not important to keep its dependencies up to date. So if the dropdown component breaks in a year or two, nobody cares.
Of course, there is also the opposite world where long-term maintenance matters a lot:
- An interactive productivity app
- A design system
- A platform with its own app store for UI components
- An online multiplayer game
I could go on, but the point is: the second group cares a lot more about long-term maintainability than the first group. If you’ve spent your entire career working on the first group, then you may indeed find shadow DOM to be baffling. You can’t possibly understand why you should be prevented from globally styling whatever you want.
Conversely, if you’ve spent your entire career in the second group, then you may be equally baffled by people who want global access to everything. (“Are they trying to shoot themselves in the foot?”) This is why I think people are often talking past each other about this stuff.
But does it work
So now that we’ve established the problem shadow DOM is trying to solve, there’s the inevitable question: does it actually solve it?
This is an important question, because I think it’s the source of the other major tension with shadow DOM. Even people who understand the problem are not in agreement that shadow DOM actually solves it.
If you want to get a good sense of people’s frustrations with shadow DOM, there are two massive GitHub threads you can check out:
There are a lot of potential solutions being tossed around in those threads (including by me), but I’m not really convinced that any one of them is the silver bullet that is going to solve people’s frustrations with shadow DOM. And the reason is that the core problem here is a coordination problem, not a technical problem.
For example, take “open-stylable shadow roots.” The idea is that a shadow root can inherit the styles from its parent context (exactly like light DOM). But then of course, we get into the coordination problem:
- Will every web component on npm need to enable open-stylable shadow roots?
- Or will page authors need a global mechanism to force every component into this mode?
- What if a component author doesn’t want to be opted-in? What if they prefer the lower maintenance costs of a small API surface?
There’s no right answer here. And that’s because there’s an inherent conflict between the needs of the component author and the page author. The component author wants minimal maintenance costs and to avoid breaking their downstream consumers with every update, and the page author wants to style every component on the page to pixel-perfect precision, while also never being broken.
Stated that way, it sounds like an unsolvable problem. In practice, I think the problem gets solved by favoring one group over the other, which can make some sense depending on the context (largely based on whether your website is in group one or group two above).
A potential solution?
If there is one solution I find promising, it’s articulated by my colleague Caridy Patiño:
Build building blocks that encapsulate logic and UI elements that are “fully” customizable by using existing mechanisms (CSS properties, parts, slots, etc.). Everything must be customizable from outside the shadow.
If a building block is using another building block in its shadow, it must do it as part of the default content of a well-defined slot.
Essentially, what Caridy is saying is that instead of providing a dropdown component to be used like this:
<snazzy-dropdown></snazzy-dropdown>
… you instead provide one like this:
<snazzy-dropdown>
<snazzy-trigger>
<button>Click ▼</button>
</snazzy-trigger>
<snazzy-listbox>
<snazzy-option>One</snazzy-option>
<snazzy-option>Two</snazzy-option>
<snazzy-option>Three</snazzy-option>
</snazzy-listbox>
</snazzy-dropdown>
In other words, the component should expose its “guts” externally (using <slot>s in this example) so that everything is stylable. This way, anything the consumer may want to customize is fully exposed to light DOM.
This is not a totally new idea. In fact, outside of the world of web components, plenty of component systems have run into similar problems and arrived at similar solutions. For example, so-called “headless” component systems (such as Radix UI, Headless UI, and Tanstack) have embraced this kind of design.
For comparison, here is an (abridged) example of the dropdown menu from the Radix docs:
<DropdownMenu.Root>
<DropdownMenu.Trigger>
<Button variant="soft">
Options
<CaretDownIcon />
</Button>
</DropdownMenu.Trigger>
<DropdownMenu.Content>
<DropdownMenu.Item shortcut="⌘ E">Edit</DropdownMenu.Item>
<DropdownMenu.Item shortcut="⌘ D">Duplicate</DropdownMenu.Item>
<!-- ... --->
<DropdownMenu.Content>
<DropdownMenu.Root>
This is pretty similar to the web component sketch above – the “guts” of the dropdown are on display for all to see, and anything in the UI is fully customizable.
To me, though, these solutions are clearly taking the burden of complexity and shifting it from the component author to the component consumer. Rather than starting with the simplest case and providing a bare-bones default, the component author is instead starting with the complex case, forcing the consumer to (likely) copy-paste a lot of boilerplate into their codebase before they can start tweaking.
Now, maybe this is the right solution! And maybe the long-term maintenance costs are worth it! But I think the tradeoff should still be acknowledged.
As I understand it, though, these kinds of “headless” solutions are still a bit novel, so we haven’t gotten a lot of real-world data to prove the long-term benefits. I have no doubt, though, that a lot of component authors see this approach as the necessary remedy to the problem of runaway configurability – i.e. component consumers ask for every little thing to be configurable, all those configuration options get shoved into one top-level API, and the overall experience starts to look like recursive Swiss Army Knives. (Tanner Linsley gives a great talk about this, reflecting on 5 years of building React Table.)
Personally, I’m intrigued by this technique, but I’m not fully convinced that exposing the “guts” of a component really reduces the overall maintenance cost. It’s kind of like, instead of selling a car with a predefined set of customizations (color, window tint, automatic vs manual, etc.), you’re selling a loose set of parts that the customer can mix-and-match into whatever kind of vehicle they want. Rather than a car off the assembly line, it reminds me of a jerry-rigged contraption from Minecraft or Zelda.

In Tears of the Kingdom, you can glue together just about anything, and it will kind of work.
I haven’t worked on such a component system, but I’d worry that you’d get bugs along the lines of, “Well, when I put the slider on the left it works, but when I put it on the right, the scroll position gets messed up.” There is so much potential customizability, that I’m not sure how you could even write tests to cover all the possible configurations. Although maybe that’s the point – there’s effectively no UI, so if the UI is messed up, then it’s the component consumer’s job to fix it.
Conclusion
I don’t have all the answers. At this point, I just want to make sure we’re asking the right questions.
To me, any proposed solution to the current problems with shadow DOM should be prefaced with:
- What kind of website or webapp is the intended context?
- Who stands to benefit from this change – the component author or page author?
- Who needs to shift their behavior to make the whole thing work?
I’m also not convinced that any of this stuff is ripe enough for the standards discussion to begin. There are so many options that can be explored in userland right now (e.g. the “expose the guts” proposal, or a polyfill for open-stylable shadow roots), that it’s premature to start asking standards bodies to standardize anything.
I also think that the inherent conflict between the needs of component authors and component consumers has not really been acknowledged enough in the standards discussions. And the W3C’s priority of constituencies doesn’t help us much here:
User needs come before the needs of web page authors, which come before the needs of user agent implementors, which come before the needs of specification writers, which come before theoretical purity.
In the above formulation, there’s no distinction between component authors and component consumers – they are both just “web page authors.” I suppose conceptually, if we imagine the whole web platform as a “stack,” then we would place the needs of component consumers over component authors. But even that gets muddy sometimes, since component authors and component consumers can work on the same team or even be the same person.
Overall, what I would love to see is a thorough synopsis of the various groups involved in the web component ecosystem, how the existing solutions have worked in practice, what’s been tried and what hasn’t, and what needs to change to move forward. (This blog post is not it; this is just my feeble groping for a vocabulary to even start talking about the problem.)
In my mind, we are still chasing the holy grail of true component reusability. I often think back to this eloquent talk by Jan Miksovsky, where he explains how much has been standardized in the world of building construction (e.g. the size of windows and door frames), whereas us web developers are still stuck rebuilding the same thing over and over again. I don’t know if we’ll ever reach true component reusability (or if building construction is really as rosy as he describes – I can barely wield a hammer), but I do know that I still find the vision inspiring.